Claude Opus 4.6 - Anthropic's latest programmable AI model
Claude Opus 4.6 is Anthropic's flagship AI model, an upgrade from Claude Opus 4.5. The model is the first to support an ultra-long context window of 1 million tokens, leading across the board in programming, inference, and complex task processing. Claude Opus 4.6 surpasses Terminal-Bench 2.0, Humanity’s Last...
Claude Opus 4.6 is the flagship AI model launched by Anthropic for Claude Opus 4.5upgraded version. For the first time, the model supports an ultra-long context window of 1 million tokens, taking the lead in programming, reasoning, and complex task processing. Claude Opus 4.6 set new records in benchmark tests such as Terminal-Bench 2.0 and Humanity’s Last Exam, and its GDPval-AA score exceeded GPT-5.2 by 144 Elo points. Newly added functions such as adaptive thinking and context compression can autonomously perform enterprise-level tasks such as financial analysis, code review, and document processing, marking a paradigm shift in AI from a tool to an autonomous agent.
Key features of Claude Opus 4.6
- Very long context handling : Claude Opus 4.6 supports a context window of 1 million tokens for the first time, reaching an accuracy of 76% in the MRCR v2 test, significantly better than the 18.5% of the previous generation model, solving the common “context rot” problem of large models.
- adaptive thinking mechanism : The model can automatically determine whether in-depth reasoning is needed based on the difficulty of the task. Developers can manually set the four thinking gears of low, medium, high, and max to flexibly balance quality, speed, and cost.
- context compression technology : Automatically compress historical conversations into summaries to make room for new content, allowing Claude to perform longer tasks without interruption due to context overflow.
- Enterprise level work ability : Can autonomously run financial analysis, legal research, document creation, spreadsheet processing, and presentation production, surpassing GPT-5.2 by approximately 144 Elo points in the GDPval-AA test.
- Programming and code review : Achieve the highest score in the Terminal-Bench 2.0 agent coding assessment, have code review, debugging, multi-language development and large code base maintenance capabilities, and can maintain long-term autonomous workflow.
- Internet information retrieval : Outperforms all other models in the BrowseComp test, is good at finding hard-to-find information online, and can process and reason about a large amount of network data combined with 1 million token context.
- Office suite integration : Directly integrated into office software through Claude in Excel and Claude in PowerPoint plug-ins, supporting pivot table editing, chart modification, slide master reading and brand consistency maintenance.
- Security and Alignment : Exhibiting low misleading rates, low flattery rates, and low over-rejection rates in automated behavioral audits, with an overall security profile that is comparable to or better than Claude Opus 4.5, making it one of the best-aligned cutting-edge models in the industry.
Performance of Claude Opus 4.6
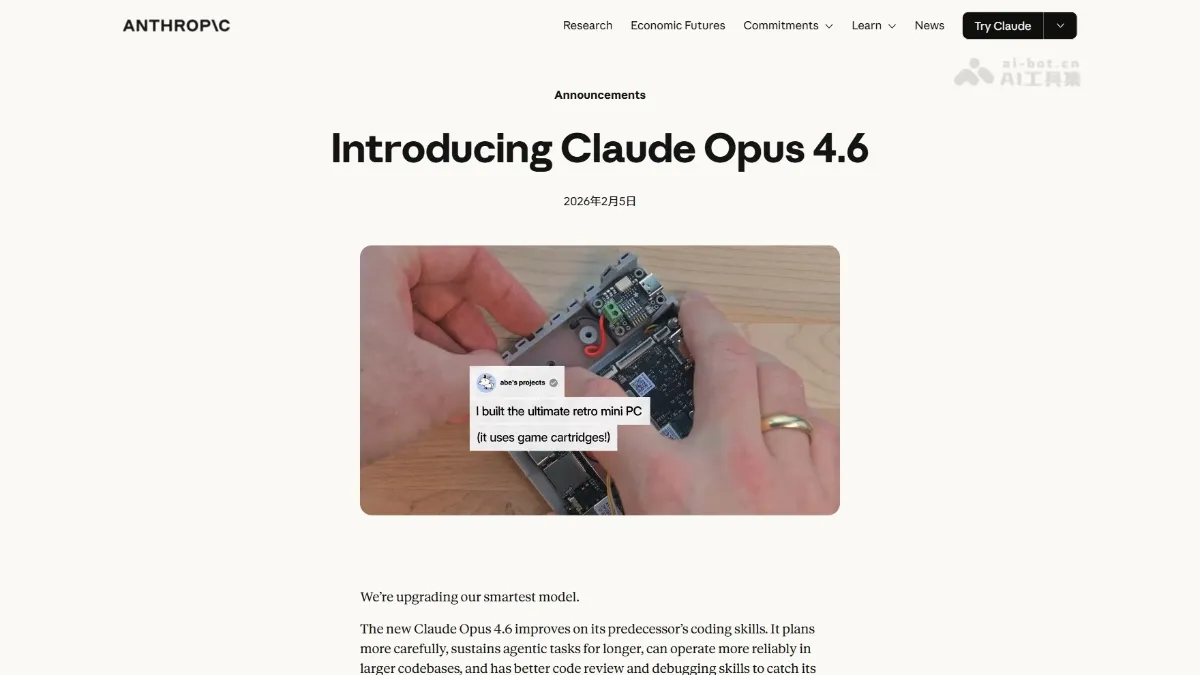
- In Terminal-Bench 2.0 Agent Coding Evaluation , Claude Opus 4.6 achieved a score of 65.4%, the highest among all models.
- In Humanity’s Last Exam Complex Multidisciplinary Reasoning Test , the Claude Opus 4.6 is ahead of all other cutting-edge models.
- In the GDPval-AA Authentic Knowledge Work Task Assessment , Claude Opus 4.6 scored 1606 Elo points, which is about 144 points higher than GPT-5.2 and 190 points higher than the previous generation Claude Opus 4.5.
- In the BrowseComp Web Information Retrieval Test , Claude Opus 4.6 achieved 84.0%, better than GPT-5.2 Pro’s 77.9%.
- On the ARC AGI 2 Fluid Intelligence Test , Claude Opus 4.6 reached 68.8%, significantly surpassing GPT-5.2 Pro’s level of more than 50%.
- On the OSWorld Computer Aptitude Test , Claude Opus 4.6 achieved 72.7%, a significant improvement from the 66.3% achieved by the previous generation Opus 4.5.
- In the MRCR v2 long context retrieval test , the 1 million token eight-pin variant achieved 76%, and Sonnet 4.5 only 18.5%.
- Code fix testing in SWE-bench Verified Among them, an average of 25 trials reaches 80.8%, and it can reach 81.42% after optimization.
How to use Claude Opus 4.6
- Use via Claude web client :Login claude You can directly access Claude Opus 4.6 without additional configuration, and the model is fully online in the web version.
- via API call : Developers can use the model name
claude-opus-4-6Make an API call. - Used in Claude Code :install Claude Code Afterwards, you can directly call Opus 4.6 through the command line to perform programming tasks, support the agent team function, and use
/effortParameter adjustment thinking gear.
Application scenarios of Claude Opus 4.6
- Software Development and Programming : Claude Opus 4.6 can be used for the review and maintenance of large code bases, and supports multi-language development environments, allowing developers to efficiently manage complex projects.
- Code debugging and repair : The model has code debugging and error repair capabilities, and can independently locate problems and generate repair plans, reducing developers’ manual troubleshooting time.
- Long-term autonomous workflow : In complex software engineering tasks, Claude Opus 4.6 can maintain long-term autonomous workflow without frequent manual intervention, making it suitable for large-scale project development.
- financial analysis : Financial analysts can use Claude Opus 4.6 to run complex financial analysis and modeling tasks and quickly generate professional reports and data insights.
- Legal document review : Legal practitioners can use the ultra-long context window to process hundreds of pages of legal document review and complete large-scale document analysis at one time. ©
You May Also Like
Voxtral Transcribe 2 - A series of speech-to-text models launched by Mistral AI
Voxtral Transcribe 2 is a new generation of speech-to-text models launched by Mistral AI, including two versions: Voxtral Mini Transcribe V2 focuses on batch transcription and supports 13 languages, speaker separation, word-level timestamps, and context bias.
Grok 4.20 - xAI's next-generation multi-agent AI model
Grok 4.20 is a next-generation multi-agent AI system launched by xAI, a company under Elon Musk. It employs a revolutionary "four-agent collaborative architecture," featuring four specialized agents: Team Leader Grok, Research Expert Harper, Logic Expert Benjamin, and Creative Expert Lucas. Through parallel thinking, multiple rounds of internal discussion, and peer review mechanisms, the system achieves highly efficient collaboration similar to a human expert team while maintaining machine-level operating speed. Grok 4.20 boasts a MoE architecture with approximately 3T parameters and supports 256K...
M2.5 - MiniMax's flagship programming model
M2.5 is MiniMax's lightweight flagship model with 10B activation parameters, emphasizing programming and agentic capabilities. The model supports an ultra-high inference speed of 100 TPS (approximately 3 times that of Claude Opus) and supports full-stack development, complex logic reasoning, and enterprise-level system construction in 10+ languages (Go, Rust, Kotlin, Python, Java, etc.).
HiClaw - Alibaba Cloud's open-source multi-agent team collaboration system
HiClaw is an open-source agent-based team collaboration system from Alibaba, positioned as a "Team version of OpenClaw." The system introduces a Manager Agent as an AI steward, automatically coordinating multiple Worker Agents to complete complex tasks. HiClaw's core highlights include: Workers do not hold real credentials (only Consumer Tokens), ensuring secure isolation and preventing leaks; a built-in Matrix server allows for real-time monitoring and intervention via mobile phone; and conversational creation...