Covo-Audio - Tencent's open-source end-to-end speech model
Covo-Audio is an open-source, 7 billion-parameter end-to-end speech model from Tencent, capable of directly processing continuous audio input and generating audio output. Its core innovations include a hierarchical trimodal speech-text interleaved architecture, decoupling technology between intelligence and speaker, and native full-duplex interaction capabilities. Built on Qwen2.5-7B and Whisper, the model achieves state-of-the-art (SOTA) performance in tasks such as spoken dialogue, speech understanding, and audio understanding. As a unified architecture for speech AI, the model avoids the latency and error accumulation of traditional cascaded systems, making it a powerful open-source alternative to GPT-4o speech capabilities. ...

Covo-Audio is Tencent’s open source 7 billion parameter end-to-end speech model that can directly process continuous audio input and generate audio output. The core innovations of the model include hierarchical three-modal voice-text interleaved architecture, intelligence and speaker decoupling technology, and native full-duplex interaction capabilities. The model is based on Qwen2.5-7BBuilt with Whisper, it achieves SOTA performance in tasks such as spoken dialogue, speech understanding, and audio understanding. As a voice AI with a unified architecture, the model avoids the delay and error accumulation of traditional cascade systems. GPT-4oA powerful open source alternative to voice capabilities.
Covo-Audio’s main features
- spoken dialogue : Supports natural multi-round dialogue interaction of end-to-end voice input and voice output.
- speech understanding : The model deeply integrates acoustic features and semantic content to achieve comprehensive analysis of high-fidelity speech signals.
- audio understanding : The model supports expansion to non-speech scenes, and has comprehensive perception capabilities for generalized audio such as environmental sounds and music.
- full duplex interaction : Natively supports low-latency real-time two-way voice communication, allowing natural interruptions and instant responses.
Key information and usage requirements for Covo-Audio
- Developer :Tencent
- Model size : 7 billion parameters (7B)
- Architecture type : End-to-end unified audio language model
- Open source version :Covo-Audio-Chat
- base model : Qwen2.5-7B (LLM backbone) + Whisper (audio encoder)
- Model format :Safetensensors, BF16 accuracy
- Paper :arXiv:2602.09823
- Open source agreement : Dedicated License (need to check the warehouse)
- Applicable scenarios : Research and experimental purposes
- Python version : ≥ 3.11 (recommended)
- Depends on installation :Pass
requirements.txtOne click installation - core dependencies :Transformers, BigVGAN, huggingface-hub
- Hardware resources : A GPU that supports BF16 inference is required (sufficient video memory is recommended), and can be deployed locally or in the cloud for inference.
Covo-Audio’s core advantages
- End-to-end unified architecture : The model breaks the traditional ASR→LLM→TTS cascade mode, realizes direct mapping from audio to audio, eliminates error accumulation and significantly reduces inference delay.
- Three-modal deep fusion : Establish effective alignment of high-fidelity prosody and robust semantics through hierarchical interleaving of continuous acoustic features, discrete speech tokens, and natural language text.
- Decoupling intelligence and timbre : The model uses multi-speaker training to separate dialogue intelligence and speaker characteristics, supporting flexible migration and personalized customization of high-quality speech.
- Native full-duplex capability : The model uses low-latency streaming processing to achieve real-time two-way interaction, supports natural interruptions and instant responses, and is close to the human conversation experience.
- Open source ecological value : The model balances performance and cost with a parameter scale of 7 billion. The openness of the complete technology stack lowers the application threshold and provides an independent and controllable base solution for Chinese voice AI.
How to use Covo-Audio
- Environmental preparation : Create a Python 3.11 environment and install dependencies, execute conda create -n covoaudio python=3.11 and conda activate covoaudio, and complete dependency installation through pip install -r requirements.txt.
- Get code : Clone the official GitHub repository locally, run git clone https://github.com/Tencent/Covo-Audio.git and enter the project directory cd Covo-Audio.
- Download model : Install HuggingFace tool and download pre-trained weights, execute pip install huggingface-hub and hf download tencent/Covo-Audio-Chat –local-dir ./covoaudio, the model will be automatically overwritten or saved in the specified directory.
- Configuration path : If you need to customize the model storage location, modify the model_dir and decode_load_path parameters in example.sh to match the actual path.
- Run inference : Execute the one-click inference script bash example.sh, or modify the audio file path in example.py to implement customized input interaction.
- Custom use : Replace the input audio path in example.py with your own file to enable end-to-end voice dialogue interaction with the model.
Covo-Audio project address
- GitHub repository :https://github.com/Tencent/Covo-Audio
- HuggingFace model library :https://huggingface.co/tencent/Covo-Audio-Chat
- arXiv technical papers :https://arxiv.org/pdf/2602.09823
Comparison of similar competing products of Covo-Audio
| Dimensions | Covo-Audio | GPT-4o (Voice) | Mini-Omni |
|---|---|---|---|
| Developer | Tencent | OpenAI | Open source community |
| Model size | 7B parameters | Undisclosed (estimated to be hundreds of B) | 2B parameters |
| Architecture | End-to-end unified | End-to-end native | End-to-end unified |
| Open source status | Completely open source | Closed source API | Open source |
| Full duplex support | Native low latency | Native support | Limited support |
| Chinese optimization | Deep optimization | Universal multilingual basic support | |
| Deployment cost | Medium (feasible with a single card) | High (API calls) | Low (lightweight) |
Covo-Audio application scenarios
- Intelligent customer service : The model supports end-to-end low-latency interaction and full-duplex interruption capabilities, enabling natural and smooth real-time voice Q&A and multi-tone personalized services.
- Smart hardware : The model can provide offline or device-cloud integrated voice assistant capabilities for smart speakers, car systems, and home central controls.
- content creation : Supports efficient generation of multi-character dialogue dubbing, podcast content and real-time voice translation services.
- Education and training : In-depth understanding of speech emotion and rhythmic details, and the construction of immersive personalized teaching interactive systems such as oral practice and virtual lecturers.
- Accessibility services : Use natural voice interaction to replace the visual interface, providing visually impaired groups and the elderly with a convenient way to obtain information and control devices without typing or touching the screen. ©
You May Also Like
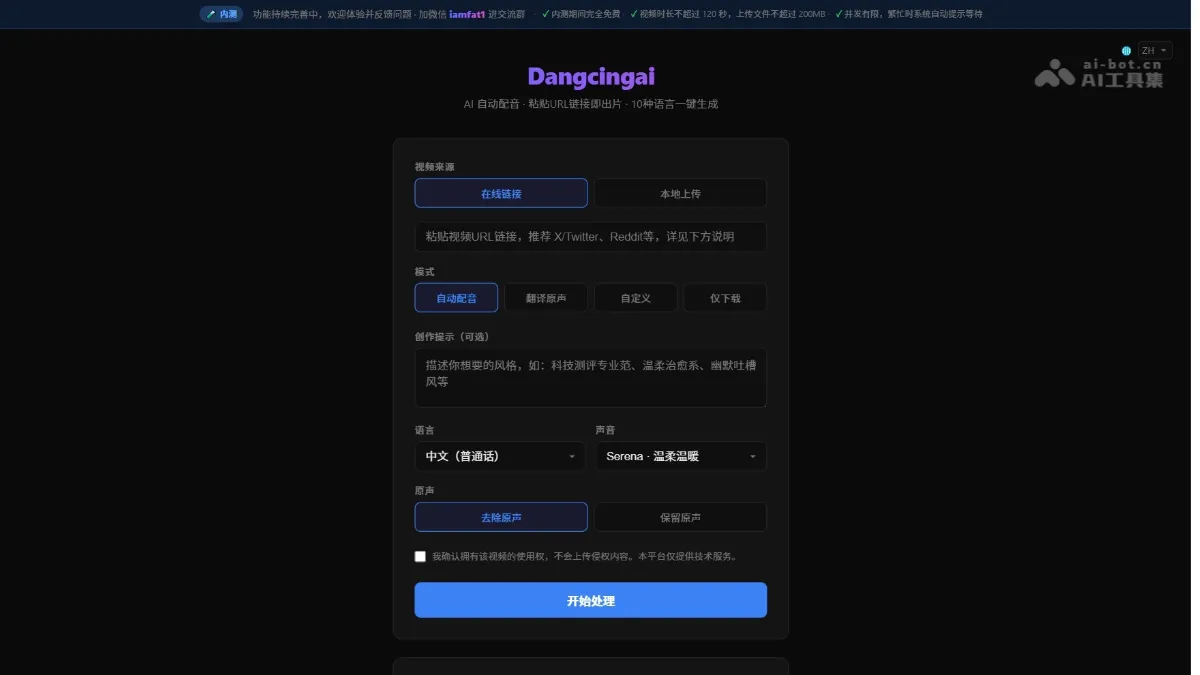
Dangcingai - An AI-powered automatic voice-over tool that supports generating multilingual dubbed videos
Dangcingai is an AI-powered automatic voice-over tool. Simply paste a video link or upload a local file to generate multilingual voice-over videos with a single click. The tool supports 10 languages, including Chinese, English, Japanese, and Korean, and offers 9 voice options. It provides three modes: automatic voice-over, original audio translation, and custom text. The AI automatically analyzes the video footage and original audio, generating scripts and synthesizing natural speech. The tool also allows adjustment of the original audio retention ratio. Dangcingai makes cross-language video creation as simple as copy and paste, making it suitable for content creation, knowledge transfer, and multilingual distribution on social media. Dangcingai's main functions...
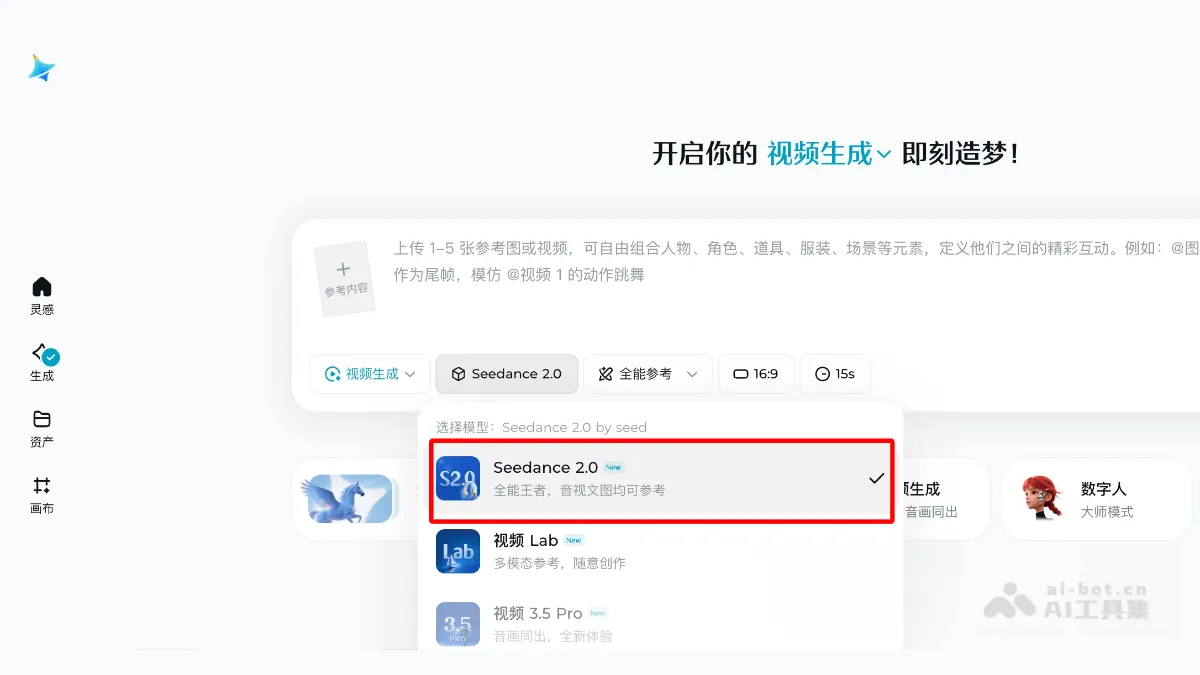
Seedance 2.0 - ByteDance's next-generation AI video generation model
Seedance 2.0 is a new generation AI video generation model launched by ByteDance's JiDream, focusing on multimodal reference and efficient creation capabilities. The model supports comprehensive reference of the first and last frames, video clips, and audio, and can accurately replicate camera movement logic, action details, and musical atmosphere, generating a 15-second video with a cost of approximately 30 points.

OpenAI Frontier - OpenAI's enterprise-grade AI agent management platform
OpenAI Frontier is OpenAI's enterprise-grade AI Agent management platform, helping enterprises build, deploy, and manage "AI colleagues." The platform empowers agents with four core capabilities: business context understanding, complex task planning and execution, continuous optimization based on real-world feedback, and clear security and permission boundaries. OpenAI Frontier seamlessly integrates with existing enterprise systems using open standards, without requiring workflow refactoring. OpenAI deploys field engineers (FDEs) to provide on-site assistance during implementation. The initial customers include...
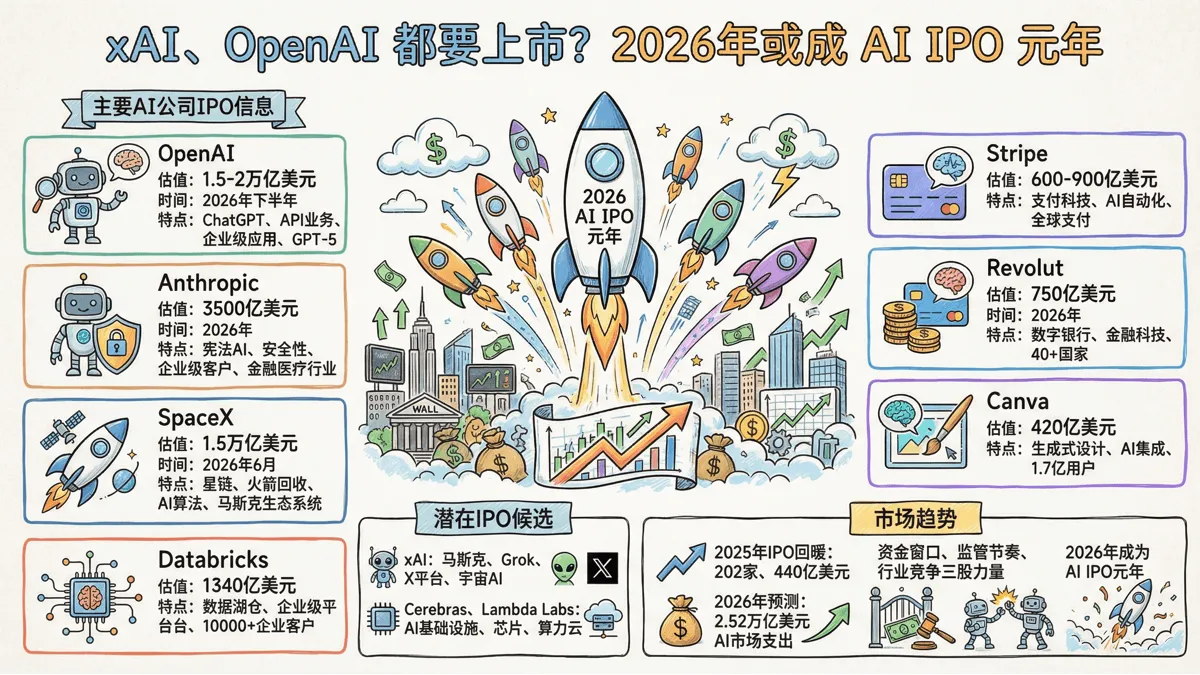
Are xAI and OpenAI going public? 2026 may be the year of AI IPOs
It's only the beginning of 2026, and Wall Street is already lining up with IPO prospectuses. In 2013, Musk stated that SpaceX would never go public, but recent news indicates he's combining rockets and AI; SpaceX and xAI plan to merge and go public this year. The IPO is expected to reach a valuation of $1.5 trillion. What made Musk suddenly change his mind?