Ctrl-World - An embodied world model jointly developed by Tsinghua University and Stanford University
Ctrl-World, a embodied world model jointly developed by Chen Jianyu from Tsinghua University and Chelsea Finn`s team from Stanford University, achieved first place globally in embodied task capability and second place globally in video generation quality in the authoritative WorldArena evaluation. The model employs a motion-conditional architecture and physics engine constraints, explicitly injecting robotic arm motion parameters into the generation process, achieving centimeter-level trajectory accuracy, a policy evaluation consistency of 0.986, and a consistency of 0.93...
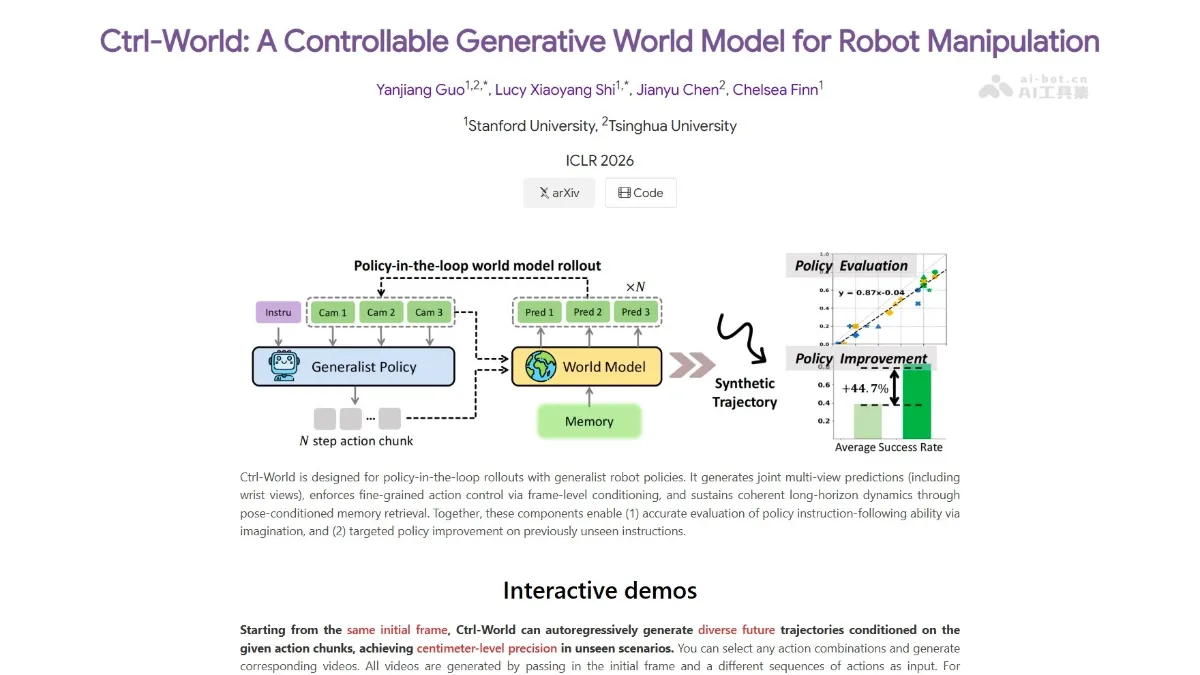
Ctrl-World is an embodied world model jointly launched by Tsinghua University’s Chen Jianyu and Stanford’s Chelsea Finn team. It ranked first in the world in embodied task capabilities and second in the world in video generation quality in the WorldArena authoritative evaluation. The model uses an action conditional architecture and physics engine constraints to explicitly inject the robot arm action parameters into the generation process, achieving centimeter-level trajectory accuracy, a policy evaluation consistency of 0.986, and a depth accuracy of 0.93, making virtual testing almost equivalent to real testing, providing a high-fidelity “digital twin” environment for robot strategy training and evaluation, and significantly reducing R&D costs.
Main functions of Ctrl-World
- strategic assessment : Supports testing robot strategies in a virtual environment. The consistency of the evaluation results with the real physical environment is as high as 0.986. Developers can complete strategy verification without building an expensive real environment.
- action planning : Based on physically accurate trajectory generation, it plans executable action sequences for the robot and supports precision operation tasks under closed-loop control.
- Data synthesis : Supports the generation of physically reasonable video-action data. The data can be directly used to train real robot strategies, solving the pain point of “virtual training and real failure” of traditional synthetic data.
- Multi-view prediction : Jointly generate multi-view RGB video, depth map and point cloud to provide the robot with complete spatial perception capabilities.
Technical principles of Ctrl-World
- action conditionalization architecture : Physical parameters such as robot joint angles and gripper opening and closing are explicitly injected into the generation process to force learning of the causal physical chain of actions and state changes, fundamentally avoiding errors that violate physical laws such as object penetration and air adsorption.
- Physics engine constraint embedding : Introducing physics engine supervision during the training process, internalizing Newton’s laws of mechanics into generating hard constraints, ensuring that the model output is not only visually realistic, but also consistent with physical conservation laws such as mass, friction, and collision.
- Memory-enhanced multi-view prediction : Maintain long-term temporal consistency through sparse historical frame retrieval and attitude conditional projection; simultaneously predict multi-view RGB, depth map and point cloud structures to achieve precise 3D spatial recognition and centimeter-level trajectory accuracy.
Project address of Ctrl-World
- Project official website :https://ctrl-world.github.io/
- GitHub repository :https://github.com/Robert-gyj/Ctrl-World
- arXiv technical papers :https://arxiv.org/pdf/2510.10125
Application scenarios of Ctrl-World
- Virtual simulation test : Developers can directly evaluate robot strategy performance in Ctrl-World without building an expensive real physical environment, significantly reducing research and development costs and time cycles.
- Strategy training data synthesis : The model generates physically reasonable video-action sequences, which can be directly used to train real robot strategies and solve the problems of high real data collection cost and low efficiency.
- Action planning and closed-loop control : Ctrl-World can generate precise action sequences for the robotic arm, support precision operation tasks such as grabbing, stacking, and insertion, and can adjust the plan based on real-time feedback during the execution process.
- Robot skill learning : By generating diverse scene and object interaction data, it helps robots learn highly generalizable operating skills and adapt to unseen object shapes, spatial positions and task instructions. ©
You May Also Like
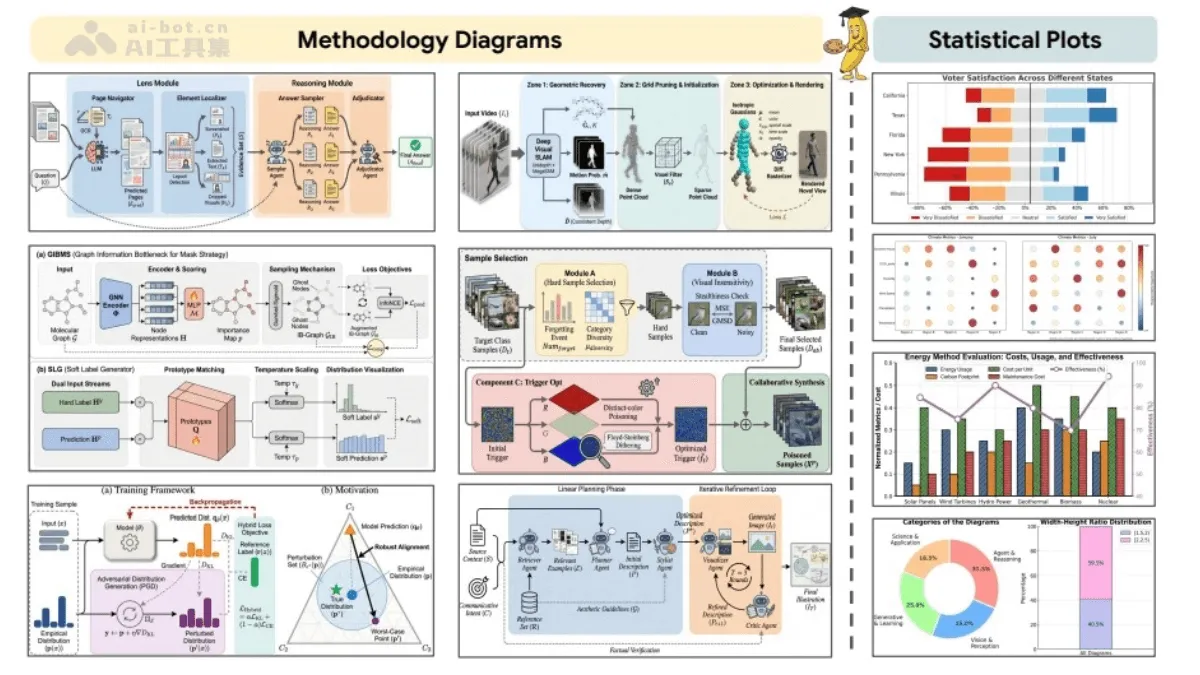
PaperBanana - An AI-powered framework for automatically generating academic illustrations, jointly developed by Peking University and Google
PaperBanana is an automated academic illustration generation framework jointly developed by Peking University and Google Cloud AI Research, addressing the pain point of time-consuming and labor-intensive data creation for AI researchers in academic papers. The system employs an innovative multi-agent collaborative architecture, comprising five specialized agents: Retriever, Planner, Stylist, Visualizer, and Critic.

Elon Musk's 3-hour conversation was full of bombshell revelations! Robots will become a "perpetual money-making machine
On February 6th reported that Elon Musk's latest nearly 3-hour interview was released on YouTube early this morning. He revealed several key figures: SpaceX is preparing for 10,000 to 20,000-30,000 launches per year, and its space computing power will exceed the global total in 5 years; Tesla's AI5 chip will be taped out and mass-produced in the second quarter of next year, with the AI6 chip launching less than a year later; Optimus will have a production capacity of one million units in 3 years and ten million units in 4 years. ...
hiData - AI data analysis and processing tool, enabling end-to-end analysis using natural language processing
hiData is an AI-driven data analysis and processing tool that allows non-technical users to process spreadsheets using natural language. Users don't need to master Excel formulas; they can simply describe their needs in plain English to complete data cleaning, analysis, calculations, and visualizations. The tool supports multiple formats including Excel, CSV, and PDF, and can automatically generate charts, reports, and presentations. Designed for marketers, researchers, and small business owners, hiData reduces data processing tasks that used to take hours to minutes, truly democratizing data analysis with "zero technical barriers."

DeepSpeed-MII - Microsoft DeepSpeed's open-source model inference library
DeepSpeed-MII is an open-source Python library from the DeepSpeed team that provides efficient model inference. DeepSpeed-MII significantly improves inference throughput and reduces latency using innovative techniques such as blocking key-value caching, sequential batch processing, and dynamic SplitFuse, demonstrating excellent performance when handling large language models.