FireRedASR2S - Xiaohongshu's open-source speech recognition model
FireRed ASR2S is a Super... on Xiaohongshu

FireRedASR2S is Xiaohongshu Super Intelligence-AudioLab open source industrial-grade end-to-end speech recognitionThe model integrates the four SOTA modules of ASR, VAD, language recognition and punctuation prediction. The model supports Chinese Mandarin and 20+ dialects, English, code switching and lyrics recognition. The Chinese Mandarin word error rate is as low as 2.89%, and the average dialect error rate is 11.55%, which is comprehensively ahead of Doubao-ASR, Qwen3-ASRWait for competing products. The system supports one-click local deployment without the need for external APIs, and has been implemented on a large scale in high-frequency scenarios such as Xiaohongshu voice comments and voice searches.
Main features of FireRedASR2S
- Speech recognition (FireRedASR2) : Supports Chinese Mandarin, 20+ dialects/accents, English, Chinese-English mixed and lyrics recognition, and provides two architecture versions: LLM and AED. The AED version supports word-level timestamps and confidence output.
- Voice Activity Detection (FireRedVAD) : The model can detect speech/singing/music, supports 100+ languages, provides streaming and non-streaming modes, and has an F1 score of 97.57%.
- Language identification (FireRedLID) : Supports recognition of 100+ languages and 20+ Chinese dialects, with an accuracy of 97.18%, significantly better than open source solutions such as Whisper.
- Punctuation prediction (FireRedPunc) : The model automatically adds Chinese and English punctuation, with an average F1 score of 78.90%, greatly improving the readability of the transcribed text.
Technical principles of FireRedASR2S
- Speech recognition (FireRedASR2) : The model adopts two architectures: Encoder-Adapter-LLM and Attention-based Encoder-Decoder. The LLM version uses large language model capabilities to achieve end-to-end speech understanding. The AED version optimizes computing efficiency on the encoder-decoder framework, integrates speech and text representation through the adapter layer, and supports timestamp and confidence output.
- Voice Activity Detection (FireRedVAD) : Based on DFSMN deep feed-forward sequence memory network, modeling audio timing characteristics. Determine the start and end points of speech through smooth windows and thresholds, distinguish voice, singing, music and other audio events, and support streaming processing to meet real-time requirements.
- Language identification (FireRedLID) : Reuse the FireRedASR2 encoder to extract speech representations and train the classifier to predict language labels. Utilize large-scale multilingual data pre-training to establish a cross-language shared representation space to achieve high-precision recognition of 100+ languages and dialects.
- Punctuation prediction (FireRedPunc) : Based on the BERT architecture, it takes unpunctuated text as input and predicts the punctuation type at each position. Through fine-tuning of Chinese and English multi-domain data, it learns text semantics and syntactic structure, and automatically inserts appropriate punctuation marks.
FireRedASR2S project address
- GitHub repository :https://github.com/FireRedTeam/FireRedASR2S
- HuggingFace model library :https://huggingface.co/collections/FireRedTeam/fireredasr2s
Application scenarios of FireRedASR2S
- Content community interaction : Support Xiaohongshu voice comments, voice search and other functions, allowing users to participate in community interaction with diverse voices such as dialects and singing, enhancing the liveliness and fun of the platform.
- Social and Communication : Enable voice private messages, voice New Year greetings and other scenarios to achieve natural and smooth voice input and real-time transcription, lower the communication threshold and improve the efficiency of emotional transmission.
- Content creation and production : Supports creative tools such as voice posting of notes, live subtitle generation, and automatic video subtitles to help creators efficiently produce multimedia content.
- Enterprise-level services : Suitable for B-side scenarios such as conference transcription, intelligent customer service, and phone analysis. The privatized deployment capabilities meet the data security compliance requirements of finance, medical and other industries. ©
You May Also Like
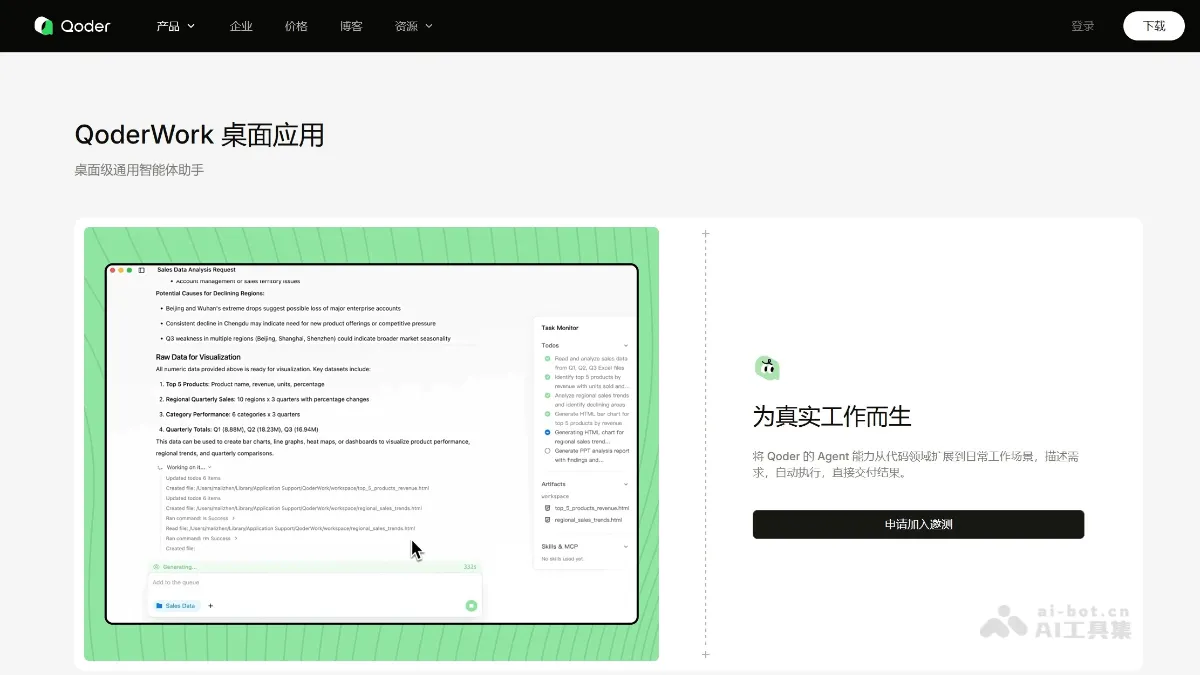
QoderWork - A desktop AI agent and toolset launched by Alibaba's Qoder team.
QoderWork is a desktop AI agent launched by Alibaba's Qoder team, aiming to be a "local AI assistant that everyone can use." It encapsulates large models, agent frameworks, MCP toolsets, and customizable skills into a single macOS application. Users can drive it to complete complex tasks in a local sandbox using a single sentence in natural language, without needing to upload files to the cloud.
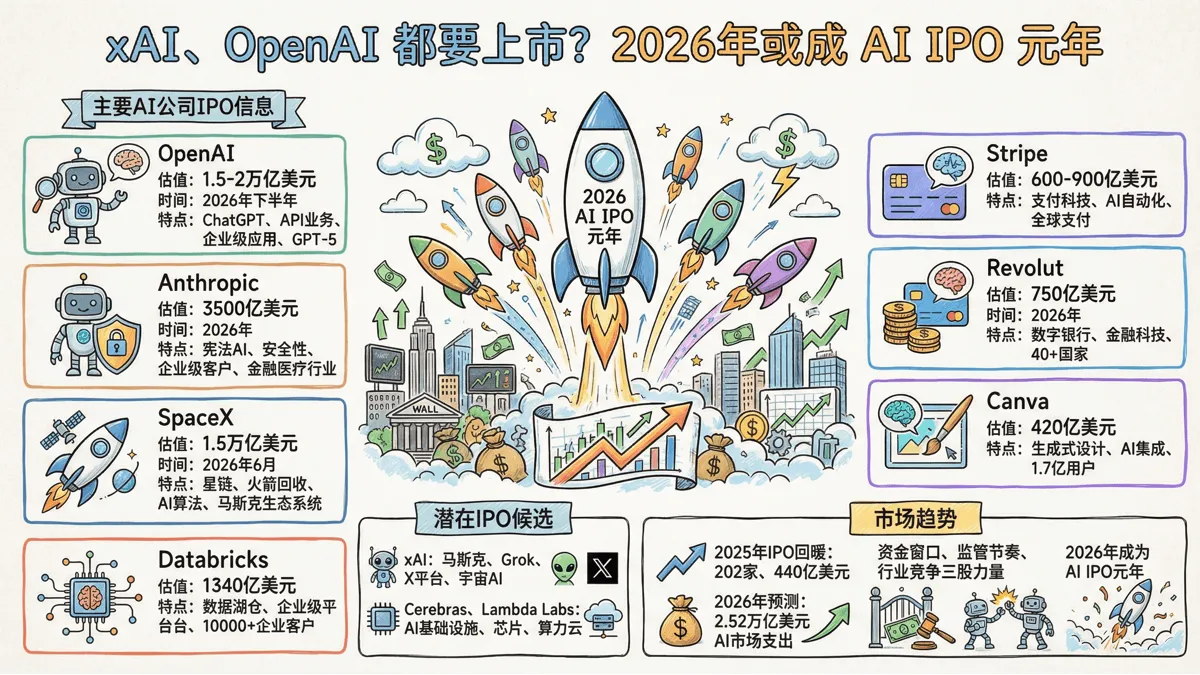
Are xAI and OpenAI going public? 2026 may be the year of AI IPOs
It's only the beginning of 2026, and Wall Street is already lining up with IPO prospectuses. In 2013, Musk stated that SpaceX would never go public, but recent news indicates he's combining rockets and AI; SpaceX and xAI plan to merge and go public this year. The IPO is expected to reach a valuation of $1.5 trillion. What made Musk suddenly change his mind?

Elon Musk's 3-hour conversation was full of bombshell revelations! Robots will become a "perpetual money-making machine
On February 6th reported that Elon Musk's latest nearly 3-hour interview was released on YouTube early this morning. He revealed several key figures: SpaceX is preparing for 10,000 to 20,000-30,000 launches per year, and its space computing power will exceed the global total in 5 years; Tesla's AI5 chip will be taped out and mass-produced in the second quarter of next year, with the AI6 chip launching less than a year later; Optimus will have a production capacity of one million units in 3 years and ten million units in 4 years. ...
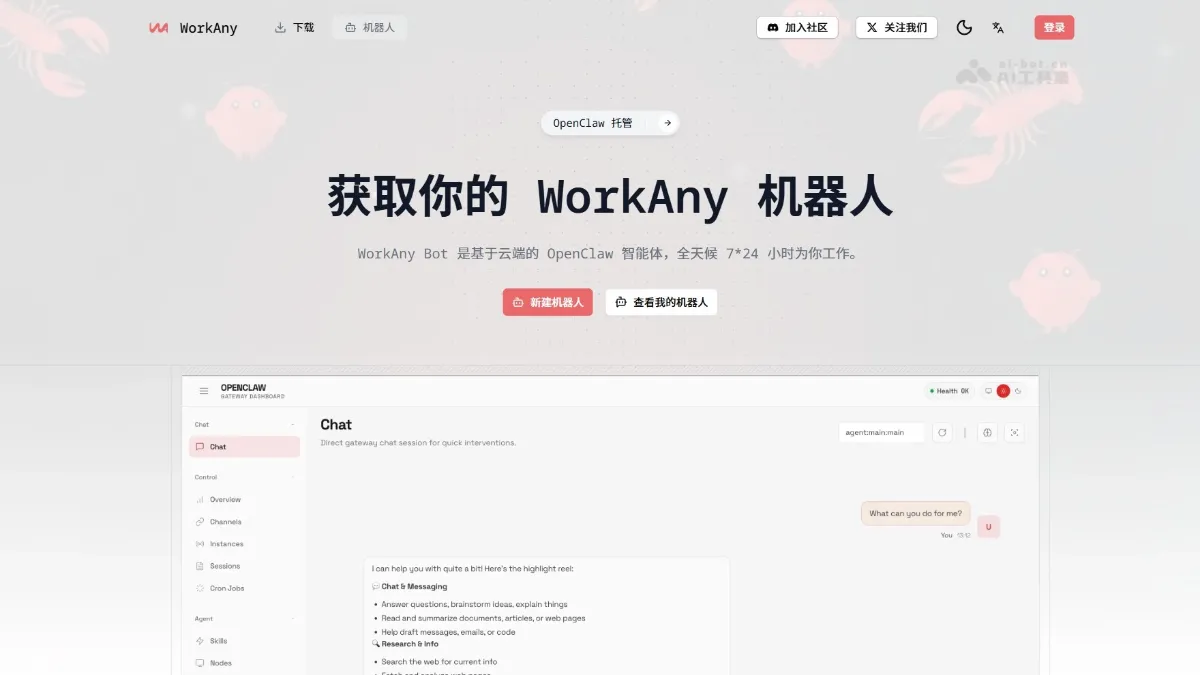
WorkAny Bot - A cloud-based AI agent tool based on the OpenClaw framework
WorkAny Bot is a cloud-based OpenClaw AI agent that supports 24/7 online work for users. WorkAny Bot supports integration with proprietary AI models such as GPT-4, Claude, and Tongyi Qianwen, and can communicate anytime through multiple channels including Telegram, Discord, Lark, and Slack.