LTX-2.3 - Lightricks' latest open-source video generation model
LTX-2.3 is the latest generation video generation model open-sourced by the Israeli AI company Lightricks. It adopts the Diffusion Transformer architecture and has 22 billion parameters. The model supports three input methods: text, image, and audio to generate videos, and can output videos at a maximum resolution of 4K. It also natively supports 9:16 portrait format and 24/48FPS frame rate selection.
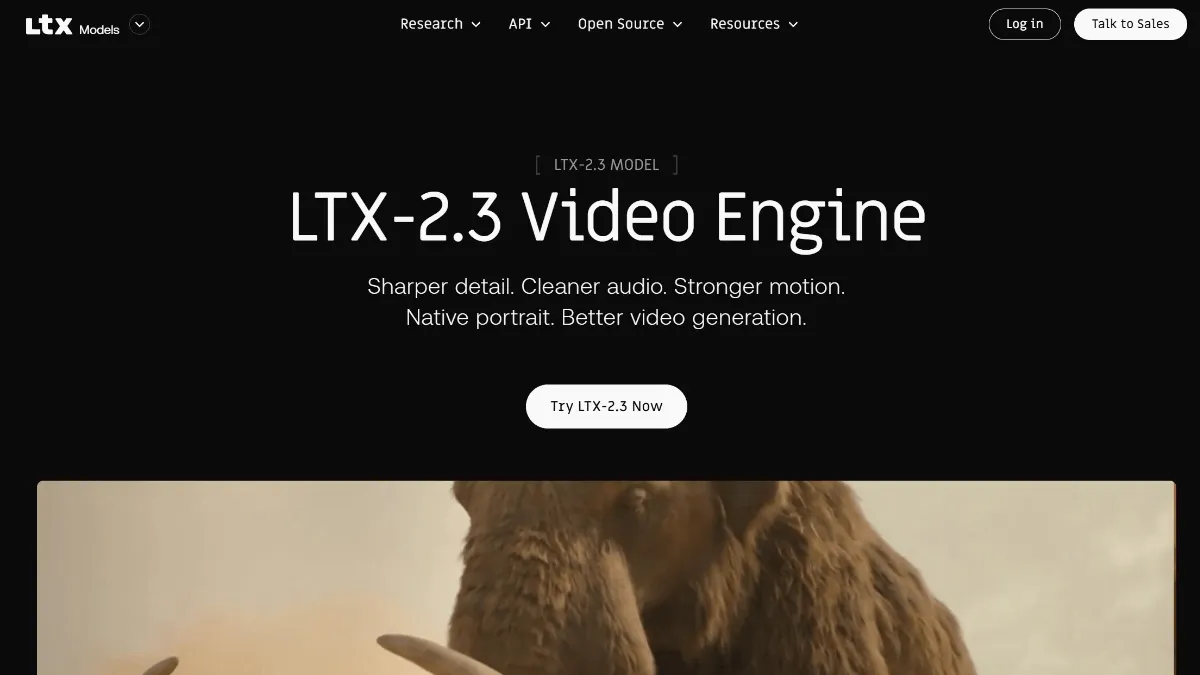
LTX-2.3 is the latest generation open sourced by Israeli AI company Lightricks video generationThe model, using the Diffusion Transformer architecture, has 22 billion parameters. The model supports three input methods: text, image, and audio to generate video, can output up to 4K resolution, and natively supports 9:16 vertical screen format and 24/48FPS frame rate selection. Compared with the previous generation, LTX-2.3 significantly improves the sharpness of picture details through a newly trained VAE architecture, solves the problem of texture blur at high resolutions, and adds a native audio generation function to achieve simultaneous audio and video output. The model provides 7 generation endpoints, can generate up to 20 seconds of video at a time, and supports LoRA fine-tuning.
LTX-2.3 main features
- Multimodal video generation : Supports three core generation methods: text-to-video (text-generated video), image-to-video (image-generated video), and audio-to-video (audio-generated video) to meet different creative needs.
- Native vertical screen support : Added 9:16 vertical screen format (up to 1080×1920), directly adapted to short video platforms and social media content creation.
- Audio and video synchronization generation : Added native audio generation function, which can simultaneously output environmental sounds, sound effects and dialogues, and can also drive video screen generation through audio input.
- Flexible frame rate selection : Supports two frame rate modes: 24FPS cinematic and 48FPS smooth motion.
- Video extension and reshooting : Provides extend-video (video extension) and retake-video (clip regeneration) functions. The maximum single generation is 20 seconds, which can be further extended through extension.
- Quick generation mode : Provide text-to-video fast and image-to-video fast accelerated versions for efficiency scenarios.
- High resolution output : Supports up to 4K resolution, achieving sharper picture details and texture performance through the new VAE architecture.
- LoRA fine-tuning support : Creators can train the LoRA adapter locally and complete customized model fine-tuning in less than an hour.
- Supporting ultra-resolution tools : Provides a post-processing model with 2x/1.5x spatial super-resolution and 2x frame rate improvement to optimize the final output quality.
- local desktop editor : Simultaneously launched LTX Desktop open source video editor, based on the LTX-2.3 engine, running completely locally without the need for a cloud.
Technical principles of LTX-2.3
- DiT diffusion Transformer architecture : Based on the Diffusion Transformer architecture, the diffusion model is combined with Transformer to generate high-quality video through an iterative denoising process, with a parameter scale of approximately 22 billion.
- New VAE variational autoencoder : The retrained Variational Autoencoder greatly improves the encoding-decoding quality, significantly improves picture sharpness, texture details and facial feature clarity, and solves the problem of blurred details under the high resolution of the previous generation.
- Space-time joint modeling : The attention mechanism of spatiotemporal separation is used to process video data, while modeling the picture content in the spatial dimension and the motion changes in the temporal dimension to ensure the temporal coherence of the generated video.
- Native audio generation module : Integrate the audio generation sub-network to achieve end-to-end synchronous generation of audio and video, support the generation of visual content driven from audio input, and ensure the synchronization of audio and video.
- Multimodal conditional injection : The three modal inputs of text, image, and audio are uniformly mapped to the latent space through different conditional encoders to achieve flexible multi-modal control.
- Distillation accelerated version : Provides a distilled version of the model, which uses knowledge distillation technology to compress the model size and improve the inference speed while maintaining quality.
- LoRA low-rank adaptation : Supports Low-Rank Adaptation technology, allowing users to quickly inject specific styles or concepts based on pre-trained models to achieve low-cost customization.
- Super-resolution post-processing : Equipped with an independent super-resolution model, it uses spatial upsampling (2x/1.5x) and frame rate interpolation (2x) technology to perform secondary optimization on the generated video.
LTX-2.3 project address
- Project official website :https://ltx.io/model/ltx-2-3
- Hugging Face :https://huggingface.co/Lightricks/LTX-2.3
- arXiv technical papers :https://arxiv.org/pdf/2601.03233
Application scenarios of LTX-2.3
- Short videos and social media content : Native 9:16 vertical screen support and 24/48FPS frame rate selection, perfectly adapted to the content creation needs of platforms such as Douyin, TikTok, and Instagram Reels.
- Advertising and Marketing Video : Quickly generate product displays and brand videos, support image to video conversion, and convert static product images into dynamic advertising materials.
- Film and television previews and concept design : Directors and producers can use text to quickly generate shot previews to verify creative concepts before launching into official shooting, reducing initial costs.
- Game and Animation Production : Generate game cutscenes, character action references, or serve as first-version materials for animation production to speed up the content production process.
- Music MV and audio and video creation : The audio-to-video function supports audio-driven image generation, which is suitable for musicians to quickly create lyric version MVs or visual soundtracks.
- Education and training content : Generate teaching demonstration videos, visualize operating steps, and transform static teaching materials into dynamic explanation content. ©
You May Also Like

Unveiling the Dark Horse of Databases Valued at Hundreds of Billions: ByteDance, Alibaba, Tencent, Microsoft, and Tesla All Use It - ZhiDongXi
Zhidx.com (WeChat Official Account: zhidxcom) Author | Cheng Qian Editor | Xin Yuan Riding the wave of AI, an open-source database startup has seen its valuation increase 2.5 times in 7 months, reaching $15 billion (approximately RMB 104.5 billion). ...

OpenJarvis - Stanford University's open-source native AI agent framework
OpenJarvis is an open-source, local AI agent framework developed by the Scaling Intelligence Lab at Stanford University. Its core concept is to make AI execution completely localized, with cloud access as an option. The framework provides five main modules: a unified model directory layer, a hardware-aware inference engine, an agent orchestration system, tool memory, and learning optimization. It can be installed with a single click using `pip install openjarvis` and offers four interaction methods: browser, desktop application, Python SDK, and CLI.

LingBot-World - An open-source interactive world model from Ant Lingbo Technology
LingBot-World is an open-source interactive world model from AntLingbo Technology. The model learns physical laws and causal relationships from large-scale game environments through a scalable data engine, achieving accurate action-driven generation. The model supports nearly 10 minutes of continuous and stable generation, with a response speed of 16 FPS and latency controlled within 1 second, while also possessing zero-shot scene generalization capabilities. The model effectively solves the pain points of scarce and costly real-world training data, and can be widely used in robot training, autonomous driving simulation, and game development, allowing intelligent agents to learn safely and efficiently through trial and error in virtual environments.
Qwen-Image-2.0 - A fundamental image generation model launched by Alibaba's Tongyi Qianwen
Qwen-Image-2.0 is a new generation image generation model launched by Alibaba's Tongyi Qianwen, supporting two core capabilities: accurate text rendering and realistic texture detail. The model supports 1k token long commands to directly output professional infographics, PPTs, and posters, and natively renders details of people, nature, and architecture at 2K resolution.