M2.5 - MiniMax's flagship programming model
M2.5 is MiniMax's lightweight flagship model with 10B activation parameters, emphasizing programming and agentic capabilities. The model supports an ultra-high inference speed of 100 TPS (approximately 3 times that of Claude Opus) and supports full-stack development, complex logic reasoning, and enterprise-level system construction in 10+ languages (Go, Rust, Kotlin, Python, Java, etc.).
M2.5 Yes MiniMaxThe launched lightweight flagship large model with 10B activation parameters, featuring Programmingwith Agentic capabilities. The model supports an ultra-high reasoning speed of 100 TPS (about 3 times that of Claude Opus), and supports full-stack development, complex logical reasoning and enterprise-level system construction in 10+ (Go, Rust, Kotlin, Python, Java, etc.) languages. The model has reached the SOTA level in benchmark tests such as SWE-Bench Verified (80.2%) and Multi-SWE-Bench (51.3%), and has “architect-level” task disassembly and planning capabilities. The model adopts Agent’s native architecture and is positioned as the main model for the next generation of digital office.
Main functions of M2.5
- Smart programming : Supports full-stack development in 10+ languages, has architect-level planning capabilities, and can complete the complete software life cycle from system design to test review.
- agentic execution : Complete complex tasks autonomously with lower token consumption and faster speed through efficient tool invocation and intelligent search.
- Office automation : Directly deliver professional-level outputs such as Word, PPT, Excel, etc., and transform industry tacit knowledge into reusable standardized skills.
- Built by experts : Support users to create custom Experts by integrating domain SOPs and core capabilities. The platform has accumulated 10,000+ experts.
- High cost performance : One hour of continuous operation at 100 TPS costs just $1, making it completely financially feasible to run complex agents infinitely.
Technical principles of M2.5
- Forge native Agent RL framework : By introducing an intermediate layer, it completely decouples the underlying training engine and Agent, supports any Agent access and optimization, and cooperates with asynchronous scheduling and tree-like merging training sample strategies to achieve approximately 40 times training acceleration and verify that the model capability scales nearly linearly with computing power and the number of tasks.
- Agentic RL algorithm and reward design : The CISPO algorithm is used to ensure the stability of large-scale training of the MoE model, and a process reward mechanism is introduced to solve the problem of long-context credit allocation. At the same time, the true time-consuming task is estimated as a reward to achieve an optimal balance between model effect and response speed.
- Efficient reasoning and task optimization : Using the reinforcement learning incentive model to efficiently dismantle complex tasks and optimize token consumption, combined with the native 100 TPS inference speed and parallel tool calling capabilities, the completion time of SWE-Bench Verified is shortened by 37% compared with M2.1, while maintaining top performance.
- Large-scale real-environment training : RL training is conducted based on 200,000+ real environments, covering programming, search, office and other scenarios. The real workflow of the company’s internal R&D, product, sales and other functions is converted into training data, and the generalization ability of the model in real tasks is continuously improved.
- Ultimate cost architecture design : Using MoE architecture to achieve high-speed and low-cost inference, it provides dual versions of 50 TPS and 100 TPS, and cooperates with the caching mechanism to reduce the output price to 1/10-1/20 of similar models, realizing the economically feasible unlimited operation of complex Agents for the first time.
M2.5 performance
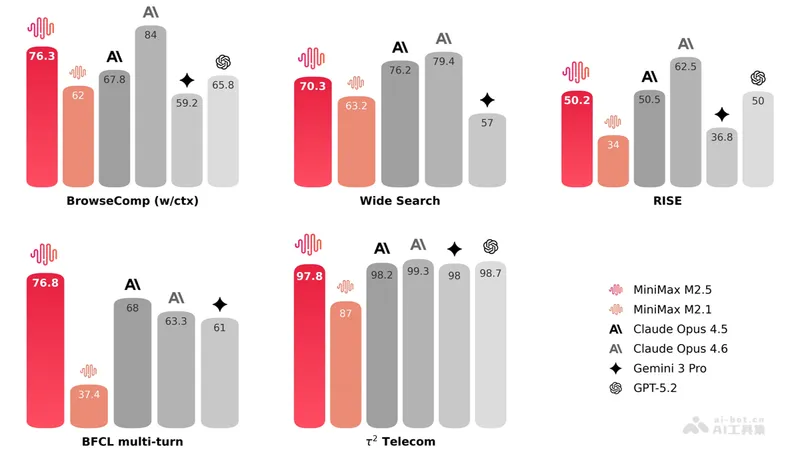
- Programming ability : Achieved a score of 80.2% in the SWE-Bench Verified test, surpassing Claude Opus 4.6 ; Ranked first in the industry with a score of 51.3% on the Multi-SWE-Bench multi-language programming benchmark; compared with the VIBE-Pro internal benchmark Opus 4.5 Performance is comparable. The generalization ability across scaffolds is excellent, with a pass rate of 79.7% on Droid, exceeding Opus 4.6’s 78.9%; on Droid OpenCode It reached 76.1%, also ahead of Opus 4.6’s 75.9%.
- Search and tool calling : Achieving an industry-leading score of 76.3% on the BrowseComp benchmark, Wide Search also leads the way. Demonstrate expert-level search abilities on the RISE Real Interactive Search assessment. Compared to the previous generation M2.1, saving about 20% of search rounds in multiple tasks, and token efficiency is significantly improved.
- Office scene : Achieved an average win rate of 59.0% on GDPval-MM, the in-house Cowork Agent evaluation framework; excelled on both the MEWC benchmark based on the Excel competition and the expert-built financial modeling evaluation.
M2.5 project address
- Project official website :https://www.minimax.io/models/text
How to use M2.5
- API call : Developers can go to the API calling platform https://platform.minimaxi.com to register an account and create an API Key to make interface calls.
M2.5 application scenarios
- Smart programming : M2.5 can automatically generate full-stack code, debug programs and optimize algorithms, significantly improving development efficiency.
- Office automation : The model can handle complex Excel data analysis tasks and automatically generate professional PPT reports.
- AI Agent : The model supports the execution of multi-step complex tasks, including in-depth research, information integration, and cross-platform automated operations.
- real-time interaction : With its high concurrent processing capabilities, the model is suitable for building real-time dialogue systems such as customer service robots and intelligent assistants. ©
You May Also Like
NemoClaw - NVIDIA's open-source enterprise-grade AI agent framework
Homepage • AI Tools • AI Projects and Frameworks • NemoClaw - NVIDIA's Open-Source Enterprise-Grade AI Agent Framework NemoClaw is an open-source enterprise-grade AI agent framework from NVIDIA. Running as a plugin for OpenClaw, NemoClaw provides a security sandbox and policy engine through the OpenShell runtime, addressing the challenges of enterprise AI...

AgentScope Java - Alibaba's open-source enterprise-level intelligent agent development framework
AgentScope Java is an open-source Java framework from Alibaba for developing enterprise-level intelligent agents, enabling Java developers to easily build production-grade AI applications. The framework adopts the leading ReAct paradigm, giving large models autonomous reasoning and planning capabilities, while providing a robust runtime control mechanism to ensure a balance between autonomy and controllability.
Tidy - A cloud-based personal AI agent that teaches AI how to use any website through demonstrations
Tidy is a cloud-based personal AI agent that allows users to interact with it anytime via iMessage or web browser. Users don't need to write code; simply demonstrate the process, and the tool will learn to use any website, transforming it into a reusable automation tool. Tidy possesses long-term memory, scheduled tasks, and file processing capabilities, helping users search for properties, book flights, and summarize news. The tool supports community tool sharing, allowing users to easily share self-built tools with friends, making AI like a helpful personal assistant always at your fingertips. Tidy's main features include: No-code tool building: Demonstrating the operation process teaches...

Fun-AudioGen-VD - A sound design model launched by Ali Tongyi Lab
Fun-AudioGen-VD is an innovative large-scale speech model launched by the speech team of Alibaba Tongyi Labs. Positioned as a professional tool for "sound design and contextualized audio generation," the model supports "FreeStyle" command generation, capable of generating high-quality audio containing specific timbre, emotional expression, and a complete auditory scene in one go based on natural language descriptions, achieving integrated sound creation of "character + scene." Regarding timbre control, Fun-AudioGen-VD...