Voxtral Transcribe 2 - A series of speech-to-text models launched by Mistral AI
Voxtral Transcribe 2 is a new generation of speech-to-text models launched by Mistral AI, including two versions: Voxtral Mini Transcribe V2 focuses on batch transcription and supports 13 languages, speaker separation, word-level timestamps, and context bias.
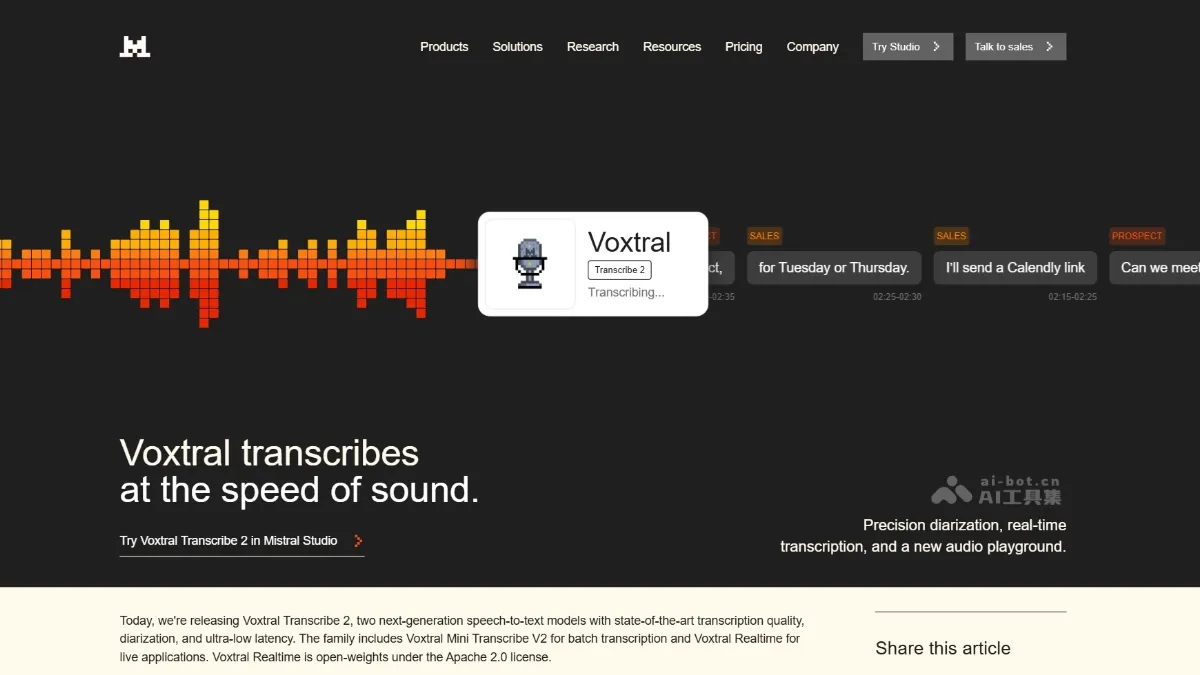
Voxtral Transcribe 2 is the next generation series from Mistral AI speech to textThe model includes two versions: Voxtral Mini Transcribe V2 focuses on batch transcription and supports 13 languages, speaker separation, word-level timestamps and context bias functions; Voxtral Realtime is specially designed for real-time scenarios and adopts a streaming architecture. The delay can be configured as low as less than 200 milliseconds, making it suitable for interactive applications such as voice assistants. The two models lead in accuracy in benchmark tests such as FLEURS, and their price/performance ratio is significantly better than GPT-4o mini , Gemini Wait for competitors.
Key features of Voxtral Transcribe 2
- Multilingual transcription : Supports high-precision speech-to-text in 13 languages including English, Chinese, Hindi, Spanish, Arabic, French, Portuguese, Russian, German, Japanese, Korean, Italian and Dutch.
- word level timestamp : Generate precise start and end times for each transcribed word, suitable for subtitle generation and content alignment.
- speaker separation : Automatically identify different speakers and mark their speaking periods, clearly distinguishing multi-party conversations.
- context bias : Supports input of up to 100 custom words to improve the accuracy of recognition of proper nouns and industry terms.
- Ultra-low latency real-time transcription : Voxtral Realtime adopts a streaming architecture, and the delay can be configured to less than 200 milliseconds, allowing you to listen and write at the same time.
- Noise robustness : Maintain high transcription accuracy in noisy environments such as factories and call centers.
- Long audio processing : A single request can process audio files of up to 3 hours.
- Multiple format support : Compatible with .mp3, .wav, .m4a, .flac, .ogg formats, single file maximum 1GB.
Technical principles of Voxtral Transcribe 2
- streaming architecture : Voxtral Realtime adopts a native streaming architecture, making its latency configurable as low as less than 200 milliseconds to meet real-time interaction needs.
- Dynamic delay configuration : The Realtime model supports flexible delay settings. When the delay is 2.4 seconds, the accuracy matches the batch model. When the delay is 480 milliseconds, the word error rate is only 1-2% higher than the offline model. Users can balance speed and accuracy according to the scenario.
- Unified multi-language modeling : Both models use a single architecture to process 13 languages, and achieve cross-language transfer through shared representation learning, enabling non-English languages to obtain recognition performance similar to English.
- context bias mechanism : The system supports injecting up to 100 custom words as prior knowledge, improving the recognition probability of specific terms during the decoding process, and optimizing the spelling accuracy of proper nouns and industry terms.
- Edge optimized design : Voxtral Realtime achieves efficient inference at a scale of 4 billion parameters, can run on consumer-grade hardware, takes into account model capabilities and deployment costs, and supports privacy-first localized processing.
Voxtral Transcribe 2 project address
- Project official website :https://mistral.ai/news/voxtral-transcribe-2
- HuggingFace model library : https://huggingface.co/mistralai/Voxtral-Mini-4B-Realtime-2602
Application scenarios of Voxtral Transcribe 2
- Conference intelligence : The model can transcribe multi-language conference recordings and clearly mark the identity of the speaker through speaker separation, process large-scale conference content at extremely low unit costs, and achieve efficient conference records and knowledge management.
- Voice Assistants vs. Virtual Assistants : Build conversational AI with ultra-low latency of sub-200 milliseconds, connect large language models and speech synthesis pipelines, and create a voice user interface that responds naturally and interacts smoothly.
- call center automation : Transcribe call content in real time, allowing the AI system to analyze customer emotions, recommend response techniques and automatically fill in CRM fields during the call. Speaker separation ensures clear distinction between agent and customer conversations.
- media and broadcasting : Generate real-time multilingual subtitles with minimal latency, and contextual biasing to accurately handle names and technical terms that common transcription services struggle to recognize. ©
You May Also Like
Qwen-Image-2.0 - A fundamental image generation model launched by Alibaba's Tongyi Qianwen
Qwen-Image-2.0 is a new generation image generation model launched by Alibaba's Tongyi Qianwen, supporting two core capabilities: accurate text rendering and realistic texture detail. The model supports 1k token long commands to directly output professional infographics, PPTs, and posters, and natively renders details of people, nature, and architecture at 2K resolution.

LingBot-World - An open-source interactive world model from Ant Lingbo Technology
LingBot-World is an open-source interactive world model from AntLingbo Technology. The model learns physical laws and causal relationships from large-scale game environments through a scalable data engine, achieving accurate action-driven generation. The model supports nearly 10 minutes of continuous and stable generation, with a response speed of 16 FPS and latency controlled within 1 second, while also possessing zero-shot scene generalization capabilities. The model effectively solves the pain points of scarce and costly real-world training data, and can be widely used in robot training, autonomous driving simulation, and game development, allowing intelligent agents to learn safely and efficiently through trial and error in virtual environments.

SoulX-FlashTalk - Soul App's open-source real-time digital human generation model
SoulX-FlashTalk is the first 14-parameter real-time digital human generation model open-sourced by Soul App's AI team, achieving sub-second latency of 0.87 seconds and a high frame rate of 32fps. The model employs bidirectional streaming distillation and a multi-step self-correction mechanism to achieve stable generation for unlimited duration, full-body motion interaction, and multi-language support. It is suitable for 24/7 live streaming, virtual customer service, game NPCs, and other scenarios. The model has already entered the HuggingFace I2V trending list...
GLM-5 - Zhipu Open Source's next-generation flagship model
GLM-5 is the next-generation flagship model open-sourced by Zhipu AI. The parameter size has been expanded from 355B in GLM-4.5 to 744B (40B activation), and the pre-training data reaches 28.5T tokens. The model is the mysterious "Pony Alpha" model that topped the OpenRouter popularity chart.