IndexCache - A sparse attention acceleration technology jointly launched by Tsinghua University and Zhipu
Homepage • AI Tools • AI Projects and Frameworks • IndexCache - A Sparse Attention Acceleration Technology Developed by Tsinghua University and Zhipu. IndexCache is a sparse attention acceleration technology developed by Tsinghua University and Zhipu. Addressing the high computational overhead of the indexer in DeepSeek Sparse Attention (DSA), it reduces redundant computation by reusing indexes across layers. IndexCache discovered that the overlap rate of the top-k tokens selected by adjacent layers is as high as...

- Home page•* AI tools *•*AI projects and frameworks *•*IndexCache – sparse attention acceleration technology launched by Tsinghua University and Zhipu
IndexCache is a sparse attention acceleration technology launched by the Tsinghua University and Zhipu teams. It solves the problem of high indexer calculation overhead in DeepSeek Sparse Attention (DSA) and reduces redundant calculations by reusing indexes across layers. IndexCache found that the overlap rate of the top-k tokens selected by adjacent layers was as high as 70%-100%, so the layers were divided into “full layers” (computing and caching indexes) and “shared layers” (directly reusing the cache). This method can remove 75% of indexer calculations, achieve 1.82x pre-filling and 1.48x decoding acceleration in a 200K context scenario, with almost no loss of model performance. It has been used in 30B parameter models and 744B parameters. GLM-5 The above verification is valid.
Main functions of IndexCache
- Cross-layer index reuse : Use adjacent layer top-k indexes with a high overlap rate of 70%-100%, allowing the shared layer to directly reuse the cache index of the full layer to avoid repeated calculations.
- Dramatically reduce indexer overhead : Removes 75% of indexer calculations, leaving only 1/4 of the indexers to maintain model performance.
- Dramatically speed up inference : Achieve pre-filling 1.82 times and decoding 1.48 times acceleration under 200K context, shortening user waiting time.
- Zero additional memory overhead : Reuse through a conditional branch without allocating additional GPU memory.
- Two deployment options are provided : The training-free scheme determines the optimal layer pattern through greedy search, and the training-aware scheme optimizes indexer parameters through multi-layer distillation loss.
- Production level verification : Validated on GLM-5 with 30B parameter model and 744B parameters, supporting SGLang and vLLM inference frameworks.
Technical principles of IndexCache
- Cross-layer index similarity discovery : The research team found through heat map analysis that the top-k token sets output by the indexers of adjacent layers of the DSA model have extremely high similarities, with overlap rates generally ranging from 70% to 100%, indicating that there is redundancy in a large number of index calculations.
- Layer role division mechanism : IndexCache divides the model layers into two categories: the Full Layer retains the original indexer and is responsible for calculating and caching the latest top-k index; the Shared Layer no longer runs its own indexer and directly reuses the index cached by the most recent full layer for sparse attention calculations.
- Dynamic mode selection strategy : For the trained model, a greedy search algorithm based on calibration data is used to try to convert the layers into shared layers one by one and evaluate the impact on the model output, retaining key layers as full layers; for scratch training scenarios, a multi-layer distillation loss is introduced, allowing each full layer indexer to learn to serve the needs of multiple subsequent shared layers at the same time.
- Reasoning process optimization : During the inference process, each layer only adds a simple conditional judgment, switches between calculating new indexes and reusing cached indexes according to the preset mode, realizing cross-layer sharing of indexers without modifying the model architecture or adding additional storage.
Key information and usage requirements of IndexCache
- Proposing organization : Jointly developed by Tsinghua University and Z.ai.
- Target the problem : Solve the computational bottleneck of the indexer in DeepSeek sparse attention in long context scenarios, accounting for up to 81% of the pre-filling time when 200K tokens are used.
- Core principles : Based on the high overlap rate of 70%-100% of the adjacent layer top-k index, redundant calculations are reduced through cross-layer reuse.
- acceleration effect : Retaining 1/4 of the indexer can achieve 1.82x pre-filling and 1.48x decoding speedup.
- performance loss : Almost no quality loss, and even performs better on some reasoning tasks.
- Validate model : Validated on both 30B parameter DSA model and 744B parameter GLM-5.
- Hardware requirements : Requires NVIDIA GPU (such as H100), but does not require additional video memory and reuses standard DSA memory space.
- software environment : Supports SGLang or vLLM framework, and provides ready-made patches that can be directly used in DeepSeek-V3.2, GLM-5 and other models.
- No training plan : Applicable to the trained DSA model, a small batch of calibration data needs to be prepared to run a greedy search to determine the optimal layer mode.
IndexCache’s core advantages
- Significant acceleration : Supports 1.82 times faster prefilling and 1.48 times faster decoding under 200K context, significantly reducing user waiting time.
- Zero performance loss : After removing 75% of indexer calculations, the model quality is almost unchanged, and some tasks are even slightly improved.
- Zero additional overhead : A conditional branch realizes reuse without increasing GPU memory usage, and reuses the memory allocated by standard DSA.
- plug and play : Provides SGLang and vLLM patches without modifying the model architecture and can be directly applied to mainstream models such as DeepSeek-V3.2 and GLM-5.
- Flexible deployment : Supports both training-free and training-aware solutions, adapts to trained models and training scenarios from scratch, and the indexer retention ratio can be flexibly configured.
- Production level verification : It has been verified to be effective on the GLM-5 large model with 744B parameters, and has the capability of large-scale deployment.
IndexCache project address
- GitHub repository :https://github.com/THUDM/IndexCache
- arXiv technical papers :https://arxiv.org/pdf/2603.12201
Comparison of similar competing products of IndexCache
| Contrast Dimensions | IndexCache | Native DSA | Full Attention Anchor method |
|---|---|---|---|
| core mechanism | Top-k index output from cross-layer reuse indexer | Each layer runs a lightweight indexer independently | Rely on full attention anchor layer reuse index |
| Computational overhead | Remove 75% of indexers, prefill speedup 1.82x | Indexer takes 81% of prefill time with 200K context | It is necessary to retain the full attention layer and the calculation cost is high |
| Applicable scenarios | DSA architecture that completely eliminates full attention | Standard DSA deployment | An architecture that requires full attention as an anchor |
| Implementation complexity | One if/else branch, zero additional video memory | Standard implementation | An anchor layer strategy needs to be designed |
| training requirements | Supports training-free deployment or training-aware optimization | Requires complete training | Usually requires joint training |
| Production verification | 744B GLM-5 Verification | DeepSeek-V3 production application | Mostly small and medium-scale experiments |
Application scenarios of IndexCache
- Long document processing : Suitable for scenarios such as paper reading and legal contract analysis, the pre-population speed is 1.82 times faster under 200K context, significantly reducing the time users wait for the first token.
- multi-step reasoning tasks : Supports complex logical chain reasoning such as mathematical proofs and code generation, decoding is accelerated by 1.48 times, and accelerates the thinking chain generation process.
- Agent workflow : Empower agentic processes such as multi-round tool invocation and autonomous task planning, reduce the cost of long-context reasoning, and support more complex agent interactions.
- RAG system : Used to enhance the generation of large-scale knowledge base retrieval, and efficiently handle the long context integration and generation of web-scale retrieval results.
- real-time conversation service : Suitable for online services such as customer service robots and intelligent assistants to increase throughput, reduce serving costs, and improve end-user experience. ©
You May Also Like

InternVL-U - An open-source multimodal integrated model from Shanghai AI Lab and other sources
InternVL-U is a lightweight, unified multimodal model with 4B parameters, open-sourced by the Shanghai Artificial Intelligence Laboratory in collaboration with several top universities. It achieves an end-to-end closed loop of "understanding-reasoning-generation-editing" for the first time. The model employs three core designs: unified contextual modeling, modality-specific modularization, and decoupled visual representation, overcoming the bottlenecks of high training costs and uneven capabilities in traditional models. The model surpasses 14B-level models in complex scenarios such as text rendering, scientific reasoning, and spatial modeling. Its GenExam benchmark score of 22.9 for scientific image generation leads all open-source unified models, providing a significant advantage for scenarios such as scientific research and education, intelligent office work, and creative content creation.
MiniMax M2.7 - MiniMax's next-generation self-evolving AI model
MiniMax M2.7 is a new generation of self-evolving AI model launched by Xiyu Technology. It can autonomously build Agent Harness, optimize its own training process, and participate in its own iteration. It performs outstandingly in software engineering, with a model SWE-Pro score of 56.22%, which is close to the international top level. It supports complex tasks such as end-to-end project delivery, bug checking, and code security.
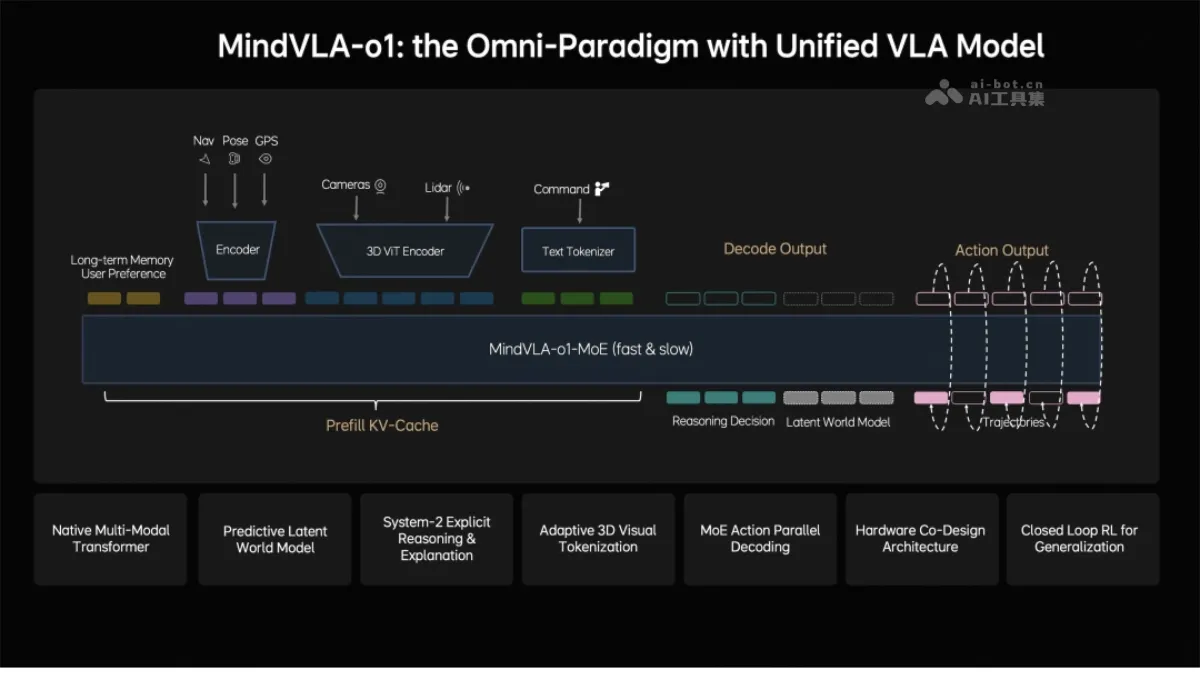
MindVLA-o1 - Li Auto's next-generation autonomous driving foundation model
MindVLA-o1 is Li Auto's next-generation autonomous driving foundation model, employing a native multimodal MoE architecture that unifies and integrates visual, linguistic, and behavioral modalities. The model achieves spatial understanding through a 3D ViT encoder, uses an implicit world model for future prediction, and outputs driving trajectories through a unified behavior generation mechanism. Combining closed-loop reinforcement learning with hardware and software co-design, MindVLA-o1 can see further, think deeper, and drive more steadily, marking a crucial step in the evolution of autonomous driving towards a general embodied intelligent agent. The main functions of MindVLA-o1...
Seedance 2.0 - ByteDance's next-generation AI video generation model
Seedance 2.0 is a new generation AI video generation model launched by ByteDance's JiDream, focusing on multimodal reference and efficient creation capabilities. The model supports comprehensive reference of the first and last frames, video clips, and audio, and can accurately replicate camera movement logic, action details, and musical atmosphere, generating a 15-second video with a cost of approximately 30 points.