LongCat-Next - Meituan's LongCat multimodal model
LongCat-Next is a multimodal model launched by Meituan's LongCat, with its core innovation being the LoZA sparse attention mechanism. The model intelligently screens the importance of modules, replacing 50% of the less important modules with streaming sparse attention, forming a ZigZag structure that interweaves global and local attention.
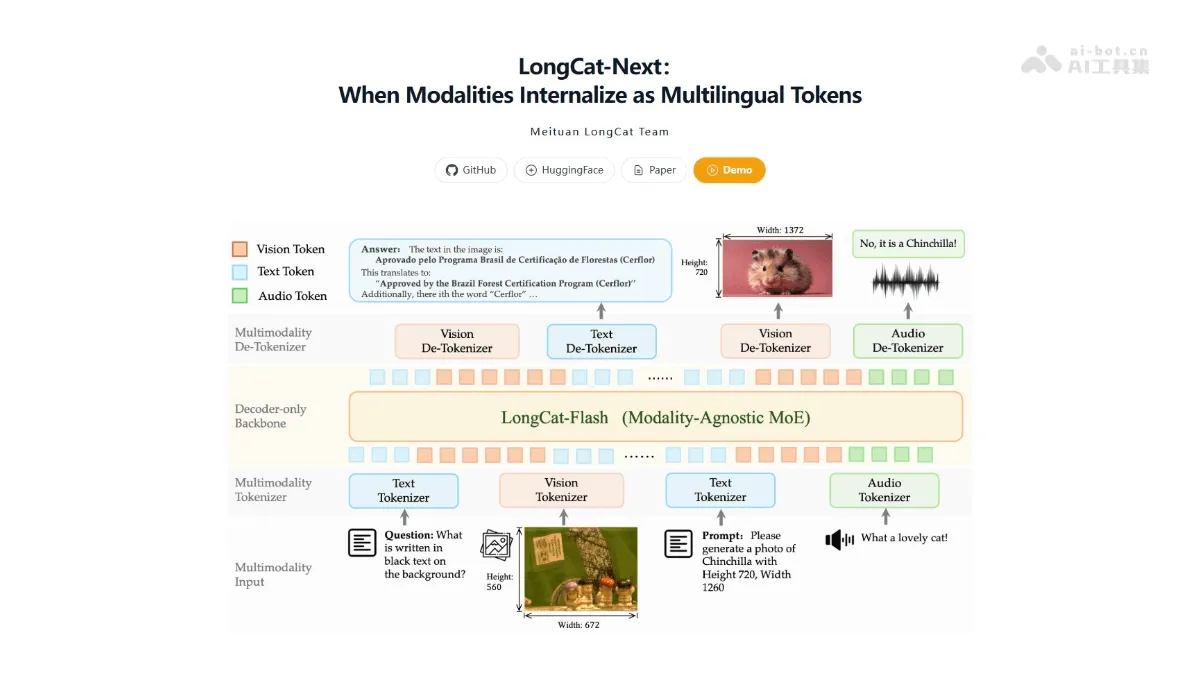
LongCat-Next is a multi-modal model launched by Meituan LongCat. The core innovation is the LoZA sparse attention mechanism. The model intelligently screens module importance and replaces 50% of low-importance modules with streaming sparse attention, forming a ZigZag structure with global and local interleaving. LongCat-Next achieves 1M ultra-long context, increases decoding speed by 10 times, saves 30% of computing power, and doubles hardware utilization. Contains two versions of Flash-Exp (1M context experimental version) and Flash-Lite (68.5B MoE architecture), and the performance of long text tasks exceeds Qwen-3.
Main functions of LongCat-Next
- Very long context understanding : Supports ultra-long text processing of 1 million Tokens, and can process twice the length of document content with the same hardware.
- LoZA sparse attention : By intelligently screening module importance and adopting ZigZag interleaved structure, efficient collaborative calculation of global and local attention is achieved.
- Inference acceleration optimization : Supports 128K context decoding speed increased by 10 times, 256K preloading speed increased by 50%, significantly reducing long text processing time cost.
- Computing cost savings : The computing power consumption during the decoding phase of the model 256K is reduced by 30%, allowing enterprises to deploy large model services at a lower cost.
- Flexible choice of dual versions : Provides an experimental version of Flash-Exp with 1M context and a lightweight version of Flash-Lite with 68.5B MoE architecture to meet the needs of different scenarios.
- Stable long text performance : Outperforming Qwen-3 in the MRCR long text benchmark test, the performance of complex document question answering and code generation tasks is more stable and reliable.
Key information and usage requirements of LongCat-Next
- publisher :Meituan LongCat Team
- core technology : LoZA (LongCat ZigZag Attention) sparse attention mechanism
- context window : Supports up to 1M Token (1 million)
- Model architecture : 68.5B MoE (hybrid expert), single inference activation 2.9B-4.5B parameters
- Performance improvements : 128K decoding is 10 times faster, 256K preloading is 50% faster, and computing power is saved by 30%.
- Hardware requirements : The specific configuration is not disclosed, but the LoZA mechanism reduces dependence on high-end hardware
- API service :LongCat-Flash-Lite provides API access and the generation speed is 500-700 token/s
LongCat-Next’s core advantages
- Ultra-long context handling capabilities : Supports 1M Token (1 million) ultra-long text understanding, and can process documents twice as long under the same hardware, breaking through the bottleneck of long text in large models.
- Efficient sparse attention mechanism : LoZA technology replaces 50% of low-importance modules with streaming sparse attention through intelligent screening of module importance to achieve accurate collaborative calculation of global and local information.
- Significant speed improvements : Model 128K context decoding speed is increased by 10 times, 256K preloading speed is increased by 50%, and long text response time is greatly shortened.
- Low computing power cost deployment : The computing power consumption in the 256K decoding stage is reduced by 30%, allowing enterprises to deploy high-performance large model services at lower hardware costs.
- Stable performance : Surpassing Qwen-3 in the MRCR long text benchmark test, daily question and answer and code generation tasks are on par with the original version, and performance in complex scenes is more reliable.
How to use LongCat-Next
- Get open source resources : Visit the GitHub repository to download the published model weights and inference code for local deployment.
- Hardware configuration : Use the LoZA sparse attention mechanism to achieve 2x longer text processing capabilities on existing hardware without upgrading high-end equipment.
LongCat-Next project address
- Project official website :https://longcat.chat/longcat-next/intro
- GitHub repository :https://github.com/meituan-longcat/LongCat-Next
- HuggingFace model library :https://huggingface.co/meituan-longcat/LongCat-Next
- technical paper :https://github.com/meituan-longcat/LongCat-Next/blob/main/tech_report.pdf
Comparison of similar competing products of LongCat-Next
| Comparative item | LongCat-Next | Qwen-3 | GPT-4 |
|---|---|---|---|
| **long text benchmark | MRCR test transcendQwen-3 | Previous leader | Unpublished MRCR data |
| context window | 1M Token | Unspecified equal length | About 128K Tokens |
| core technology | LoZA sparse attention | traditional full attention | Undisclosed details |
| Reasoning speed | 128K decoding 10 times faster | Undisclosed quantitative data | High computing power dependence |
| Computing cost | Save 30%** , hardware utilization doubled | Standard consumption | Higher API cost |
Application scenarios of LongCat-Next
-
Intelligent processing of long documents : Supports in-depth understanding, summary generation and cross-chapter information retrieval of million-word legal contracts, academic papers, and technical documents, solving the context truncation problem of traditional models.
-
Code warehouse level development assistance : The model can analyze the entire large code base (such as a million-line project) to achieve cross-file dependency understanding, global refactoring suggestions and long-context code generation.
-
Enterprise Knowledge Base Q&A : Build an intelligent customer service and decision support system based on massive internal documents to achieve high-precision long text retrieval and reasoning at lower computing power costs.
-
Multimodal long content analysis : In the future, it will support long video script analysis, long image and text content understanding, and realize the integration and generation of cross-modal long sequence information. ©
You May Also Like

Unveiling the Dark Horse of Databases Valued at Hundreds of Billions: ByteDance, Alibaba, Tencent, Microsoft, and Tesla All Use It - ZhiDongXi
Zhidx.com (WeChat Official Account: zhidxcom) Author | Cheng Qian Editor | Xin Yuan Riding the wave of AI, an open-source database startup has seen its valuation increase 2.5 times in 7 months, reaching $15 billion (approximately RMB 104.5 billion). ...
Intern-S1-Pro - An open-source scientific multimodal large model from Shanghai AI Lab
Intern-S1-Pro is a trillion-parameter scientific multimodal model open-sourced by the Shanghai AI Lab. It employs the MoE architecture (1T total parameters, 22B activations) and is built upon the "general-specific-general" SAGE technology. The model is endowed with "physical intuition" through Fourier positional encoding and reconstructed temporal encoders, enabling a unified understanding of everything from microscopic life signals to macroscopic cosmic fluctuations. It excels in Olympiad-level mathematical reasoning, the five major scientific disciplines (chemistry, materials science, life sciences, earth sciences, and physics), and real-world research scenarios. It is the world's largest open-source scientific multimodal model in terms of parameter size, propelling AI4S from a "tool revolution" to a "scientific revolution"...
HiDreamClaw - A multimodal native AI agent application and AI toolkit launched by Zhixiang Future.
HiDreamClaw is the first multimodal application product launched by Zhixiang Future, known as "Lobster," and is the first to be integrated with the overseas creative platform vivago.ai. Unlike general-purpose agents, the product has built-in HiDream AIGC Skills, directly supporting the entire process of image/video generation, copywriting, and inspiration organization, and integrating self-developed models with top models such as Veo and Sora.

Finally, Apple supports the Claude Agent SDK!
Apple and Anthropic jointly announced early this morning that Xcode, the official programming tool for Apple platform developers, has released version 26.3, and for the first time natively integrates Claude Agent, supporting development in Agentic Coding mode. In addition to Claude Agent, Xcode 26.3 also supports integration with OpenAI's Codex code agent. ...