Open-source audio and video generation models such as daVinci, MagiHuman, and Sand.ai | AI toolsets
daVinci-MagiHuman is an open-source audio and video co-generation foundation model jointly developed by the GAIR Lab at Shanghai Institute of Innovation and Technology and Sand.ai. The model employs a single-stream Transformer architecture with 15 billion parameters, uniformly modeling text, video, and audio modalities without requiring cross-attention mechanisms.

daVinci-MagiHuman is an audio and video joint generation base model jointly open sourced by Shanghai Innovation Institute GAIR Laboratory and Sand.ai. The model adopts a single-stream Transformer architecture with 15 billion parameters to uniformly model the three modes of text, video, and audio without the need for cross-attention mechanisms. The model is good at character-centered generation and supports multiple languages such as Chinese, English, Japanese, Korean, German, and French. It can generate a 5-second 256p video in 2 seconds on a single H100. Compared with Ovi 1.1 and LTX 2.3, which achieved 80% and 60.9% winning rates respectively, the code, model weights and online demo have been fully open source.
daVinci-MagiHuman’s main features
- Audio and video joint generation : Supports simultaneous generation of character videos with natural speech and lip synchronization, achieving true integrated audio and video output.
- Multi-language support : Supports speech generation in Chinese (Mandarin and Cantonese), English, Japanese, Korean, German, French and other languages.
- Portrait deduction generation : Focus on the central scene of the character and generate expressive facial expressions, body movements and emotional communication.
- Extremely fast reasoning : Supports the generation of 5-second 256p video in 2 seconds on a single H100 GPU to meet real-time interaction requirements.
- High resolution output : Through hidden space super-resolution technology, it can be expanded to 540p or 1080p high-definition video.
daVinci-MagiHuman’s technical principles
- Single-stream unified architecture : daVinci-MagiHuman uses a single-stream Transformer architecture to unify text, video, and audio into the same 15 billion parameter, 40-layer denoising network, and uses a pure self-attention mechanism to complete joint modeling, completely abandoning cross-attention or modality-specific branches. The architecture adopts a “sandwich” design, with a few layers at the beginning and end retaining modality-related parameters, and the middle backbone network sharing parameters to achieve a balance between modality specialization and deep fusion; at the same time, mechanisms such as explicit timestep conditional injection and Attention-Head gating are introduced to improve training stability and expression capabilities.
- latent space super-resolution : The model adopts a two-stage pipeline: the bottom model first generates low-resolution audio and video latent variables, and then directly completes high-resolution refinement in latent space through latent space super-resolution to avoid additional VAE encoding and decoding overhead. The audio latent variables will continue to be input into the super-resolution model to maintain the lip synchronization effect.
- Inference acceleration optimization : In the inference phase, the lightweight Turbo VAE decoder is used to reduce latency, and the self-developed MagiCompiler is integrated for full-graph compilation and optimization, which brings about 1.2 times acceleration through cross-layer operator fusion; combined with DMD-2 distillation technology, it achieves high-quality generation with only 8 steps of denoising.
Key information and usage requirements for daVinci-MagiHuman
- Model size : 15 billion parameters, 40 layers Transformer
- Architectural features : Single-stream unified architecture, pure self-attention, no cross-attention
- generative ability : Supports text/image-driven joint generation of portrait audio and video
- Supported languages : Chinese (Mandarin, Cantonese), English, Japanese, Korean, German, French
- Reasoning speed : 2 seconds to generate 5 seconds of 256p video and 38 seconds to generate 1080p video on a single H100
- Performance : Compared with Ovi 1.1, the winning rate is 80.0%, compared with LTX 2.3, the winning rate is 60.9%
- Hardware : NVIDIA GPU (H100 recommended), needs to support CUDA
- software environment : Python 3.12, PyTorch 2.9.0, CUDA 12.x
- Dependent components :Flash Attention (Hopper architecture), MagiCompiler (self-developed compiler), Turbo VAE
The core advantages of daVinci-MagiHuman
- Simple and efficient architecture : Use single-stream Transformer to uniformly model text, video, and audio, bid farewell to cross-attention and modal branches, reduce system complexity, and make training and inference optimization more direct.
- Accurate audio and video synchronization : Native joint modeling ensures high coordination of voice, mouth shape, expression, and movement, and avoids the problem of insufficient semantic alignment of audio and video in traditional solutions.
- Very fast generation : Supports the generation of 5-second 256p video in 2 seconds on a single H100, and combines latent space super-resolution, Turbo VAE, full-image compilation and model distillation to achieve real-time inference.
- Strong multilingual generalization : Supports multiple languages such as Chinese, English, Japanese, Korean, German, French and Cantonese to meet the needs of global content generation.
- Outstanding expression of portraits : Focus on the central scene of the character, generate emotional facial expressions, natural voice and realistic body movements, achieving interpretation-level quality.
How to use daVinci-MagiHuman
- Method 1: Docker Pull the pre-built image:
docker pull sandai/magi-human:latest. - Start the container and mount the local directory:
docker run -it --gpus all --network host --ipc host -v /path/to/repos:/workspace -v /path/to/checkpoints:/models sandai/magi-human:latest bash. - After entering the container, install MagiCompiler and clone the daVinci-MagiHuman code repository.
- Download the model weights from HuggingFace and update the paths in the configuration file.
- Run the corresponding script to start generation. Method 2: Conda manual installation
- Create a Python 3.12 environment and activate it:
conda create -n davinci python=3.12 && conda activate davinci. - Install PyTorch 2.9.0 and related components.
- Compile and install Flash Attention (Hopper architecture version).
- Clone and install MagiCompiler and daVinci-MagiHuman project dependencies.
- Download external models and project weights such as T5 Gemma, Stable Audio, Wan2.2 VAE, etc.
- Run the build script after updating the model path in the configuration file. run script
- Base 256p Build: Execute
bash example/base/run.sh. - Distillation Express 256p (8-step denoising, no CFG): Execute
bash example/distill/run.sh. - Superscore to 540p: Executed
bash example/sr_540p/run.sh. - Superscore to 1080p: Executed
bash example/sr_1080p/run.sh.
daVinci-MagiHuman project address
- GitHub repository :https://github.com/GAIR-NLP/daVinci-MagiHuman
- HuggingFace model library :https://huggingface.co/GAIR/daVinci-MagiHuman
- arXiv technical papers :https://arxiv.org/pdf/2603.21986
- Experience Demo online :https://huggingface.co/spaces/SII-GAIR/daVinci-MagiHuman
Comparison of similar competing products of daVinci-MagiHuman
| Comparative item | daVinci-MagiHuman | LTX 2.3 | Ovi 1.1 |
|---|---|---|---|
| R&D party | Shanghai Chuangzhi Academy GAIR + Sand.ai | Lightricks | Ovi Labs |
| Architecture design | Single-stream Transformer, no cross-attention | Multi-stream or diffuse architecture | multi-stream architecture |
| Model size | 15 billion parameters | Undisclosed | Undisclosed |
| Audio and video generation | Native joint modeling, synchronous generation | support | support |
| Generation speed | 2s/5s 256p on H100 | slower | slower |
| visual quality | 4.80 | 4.76 | 4.73 |
| text alignment | 4.18 | 4.12 | 4.10 |
| physical consistency | 4.52 | 4.56 | 4.41 |
| Audio quality (WER) | 14.60% | 19.23% | 40.45% |
| Manual evaluation winning rate | benchmark | 60.9% winning rate | 80.0% winning rate |
| Open source level | Complete open source (code + weight + tool chain) | Partially open source | Partially open source |
| Multi-language support | Chinese, English, Japanese, Korean, German, French + Cantonese | limited | limited |
Application scenarios of daVinci-MagiHuman
- AI digital human anchor : Automatically generate product delivery or news broadcast videos with accurate mouth shapes and natural expressions, and support multi-language to adapt to different regional markets.
- Virtual customer service and assistant : Create an intelligent customer service image with real voice interaction capabilities to improve service temperature and user experience.
- Film, television and advertising production : Quickly generate close-ups of characters, dubbing samples or storyboard previews to reduce pre-production costs and time.
- Education and training content : Generate multi-language teaching videos, allowing virtual lecturers to explain knowledge points with vivid expressions and clear mouth movements.
- Games and Metaverse Characters : Empower virtual characters with real-time voice-driven capabilities to achieve natural dialogue and interaction between players and NPCs. ©
You May Also Like

Nanobot - An open-source personal AI assistant from the Data Science Lab at the University of Hong Kong
Nanobot is an ultra-lightweight personal AI assistant open-sourced by the Data Intelligence Laboratory at the University of Hong Kong. It fully replicates the core functionality of the OpenClaw agent in approximately 4,000 lines of code. Nanobot possesses capabilities such as web search, file operations, scheduled tasks, and a memory mechanism, supporting scenarios including 24/7 real-time market analysis, full-stack development, schedule management, and personal knowledge bases.

OpenAI Frontier - OpenAI's enterprise-grade AI agent management platform
OpenAI Frontier is OpenAI's enterprise-grade AI Agent management platform, helping enterprises build, deploy, and manage "AI colleagues." The platform empowers agents with four core capabilities: business context understanding, complex task planning and execution, continuous optimization based on real-world feedback, and clear security and permission boundaries. OpenAI Frontier seamlessly integrates with existing enterprise systems using open standards, without requiring workflow refactoring. OpenAI deploys field engineers (FDEs) to provide on-site assistance during implementation. The initial customers include...
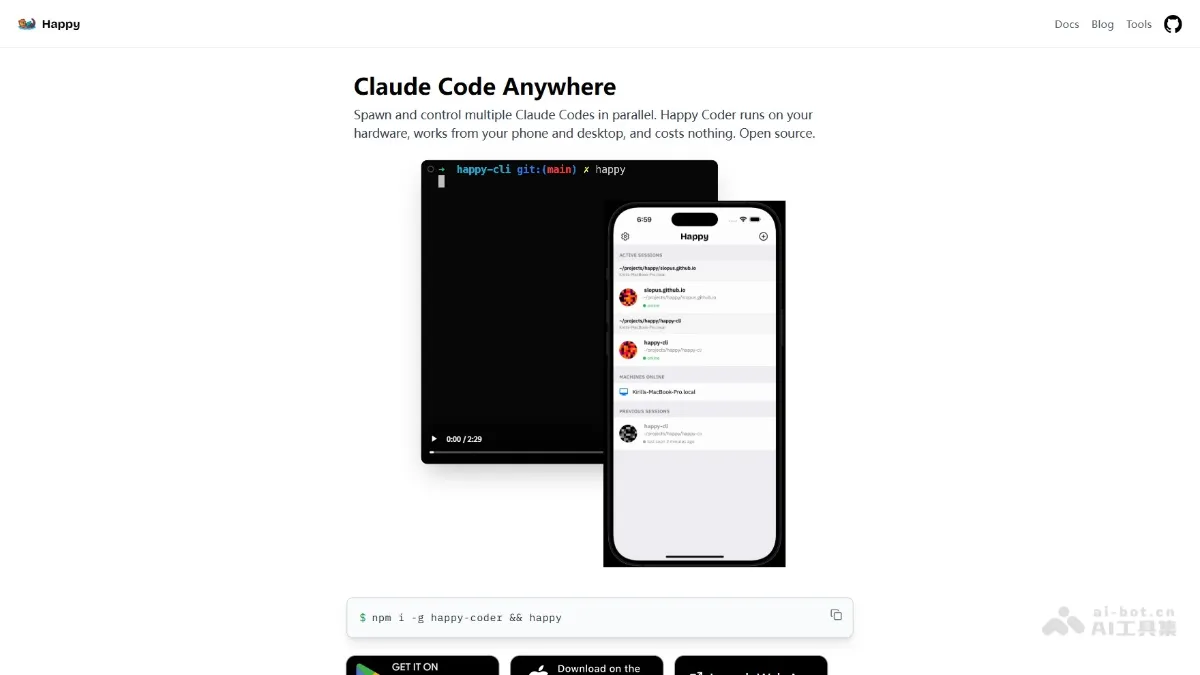
Happy - An open-source AI programming remote control tool for real-time status monitoring
What is Happy? Happy is an open-source tool that allows users to remotely control Claude Code or Codex running on their computers via mobile phones or web clients. It supports real-time code progress monitoring, voice interaction, and push notifications, and employs end-to-end encryption to ensure data security. Users simply need to install the CLI on their computers, start the service, and scan a QR code with their mobile phones to complete pairing, achieving seamless switching across devices.
DeskClaw - An all-in-one AI desktop assistant with persistent memory
DeskClaw is a desktop-based AI pet assistant, positioned as a digital employee. Running locally on the OpenClaw kernel, it boasts lightning-fast response times. DeskClaw can answer questions and directly control the system and browser to complete tasks for users. The tool integrates with Lark, DingTalk, and WeChat Work; simply invite users to groups and mention it for collaboration. DeskClaw comes with a rich built-in skill set, from information organization to market research, ready to use out of the box, providing employees, creators, and managers with a 24/7 AI assistant. DeskClaw's main functions include intelligent interaction: the tool uses AI...