MindVLA-o1 - Li Auto's next-generation autonomous driving foundation model
MindVLA-o1 is Li Auto's next-generation autonomous driving foundation model, employing a native multimodal MoE architecture that unifies and integrates visual, linguistic, and behavioral modalities. The model achieves spatial understanding through a 3D ViT encoder, uses an implicit world model for future prediction, and outputs driving trajectories through a unified behavior generation mechanism. Combining closed-loop reinforcement learning with hardware and software co-design, MindVLA-o1 can see further, think deeper, and drive more steadily, marking a crucial step in the evolution of autonomous driving towards a general embodied intelligent agent. The main functions of MindVLA-o1...
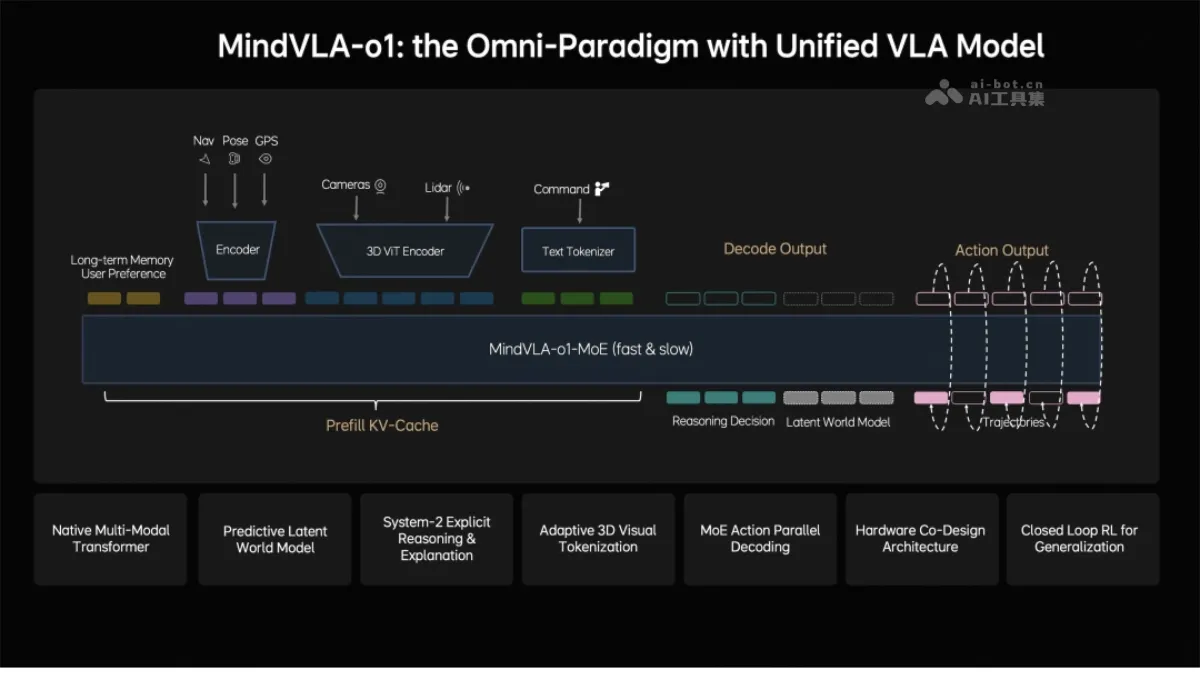
MindVLA-o1 is the next-generation autonomous driving basic model launched by Li Auto. It adopts a native multi-modal MoE architecture and integrates three modes: vision, language and behavior. The model achieves spatial understanding through the 3D ViT encoder, uses the implicit world model for future prediction, and outputs driving trajectories with a unified behavior generation mechanism. Combining closed-loop reinforcement learning with software and hardware co-design, MindVLA-o1 can see further, think deeper, and act more steadily, marking a key step in the evolution of autonomous driving to universal embodied intelligence.
Main functions of MindVLA-o1
- 3D space perception : MindVLA-o1 realizes three-dimensional space perception through 3D ViT encoder and feed-forward 3DGS representation, and accurately understands the static environment and dynamic objects in the scene.
- Multimodal thinking and reasoning : The model introduces a predictive hidden world model to deduce future scene evolution in the hidden space, achieving deep integration of visual understanding and language reasoning.
- Unified behavior generation : The system uses VLA-MoE architecture and parallel decoding mechanism to generate high-precision driving trajectories that comply with dynamic constraints and meet real-time requirements.
- Closed loop self-evolution : Based on the Feed-forward scene reconstruction and reinforcement learning framework, the model continues to evolve itself in the simulation environment, breaking through the limitations of real data scale.
- Efficient device-side deployment : Through the optimization of software and hardware co-design laws, the system can be efficiently deployed on the vehicle end-side chip, taking into account model accuracy and reasoning efficiency.
Technical principles of MindVLA-o1
- 3D self-supervised visual coding : The model’s vision-centered 3D ViT encoder uses LiDAR point clouds as geometric cues, introduces feed-forward 3DGS representation to model static environments and dynamic objects respectively, and implements self-supervised training through the next frame prediction task, so that the model has both semantic understanding and three-dimensional perception capabilities.
- Predictive hidden world model : In order to avoid the high computational cost of directly generating future images, the model performs efficient predictions in a compact latent space. After three-stage training, it builds the latent space representation and deduction capabilities of future scenes, achieving the unification of understanding the present, imagining the future, and logical judgment.
- Unified behavior generation : The Action Expert in the VLA-MoE architecture specializes in driving trajectory generation. It uses parallel decoding to output all trajectory points at once to meet real-time performance. It performs multiple rounds of iterative optimization through discrete diffusion to ensure that the trajectory space is continuous and consistent with dynamic constraints.
- Closed-loop reinforcement learning : Upgrade traditional stepwise optimization reconstruction to feed-forward scene reconstruction, combine with generative models to expand simulation capabilities, and rely on a unified 3DGS rendering engine and distributed training framework to achieve a low-cost and efficient reinforcement learning closed loop.
- Software and hardware co-design : Based on the Roofline model to describe hardware constraints, it evaluates nearly 2,000 architectural configurations to find the Pareto optimal solution for accuracy and latency. It is found that wider and shallower model architectures are more efficient in the device-side scenario, shortening the architecture exploration cycle from months to days.
Key information and usage requirements for MindVLA-o1
- Positioning : Li Auto’s next-generation autonomous driving basic model, a native multi-modal VLA architecture for embodied intelligence.
- Release time : On March 17, 2026, it was officially released by Zhan Kun, the person in charge of the base model, at NVIDIA GTC 2026.
- Five major technological innovations : 3D space understanding, multi-modal thinking, unified behavior generation, closed-loop reinforcement learning, software and hardware collaborative design.
- technological evolution : From end-to-end to VLA to native multi-modality, it represents the beginning of the physical AI era.
- Application extension : The same set of VLA models can control vehicles and robots. Autonomous driving is only the starting point of physical AI.
- data level : Rely on the MindData unified VLA data engine to continuously collect, clean and automatically label large-scale driving data.
- Computing power level : Need to cooperate with MindSim controllable multi-modal world model and RL Infra reinforcement learning infrastructure to support large-scale closed-loop training.
- hardware level : Deployed based on NVIDIA Drive Orin or Thor platform, it needs to meet the Pareto optimal configuration of model accuracy and inference delay.
- simulation level : Relying on the unified 3DGS rendering engine and distributed training framework to achieve low-cost and efficient reinforcement learning iterations.
Core advantages of MindVLA-o1
- Native multi-modal unified architecture : MindVLA-o1 incorporates the three modalities of vision, language, and behavior into the same framework for joint training and alignment without post-splicing, achieving higher efficiency and better generalization capabilities.
- Deep understanding of 3D space : Through the 3D ViT encoder and feed-forward 3DGS representation, the model has both semantic understanding and three-dimensional perception capabilities, breaking through the limitations of traditional BEV flat scenes and too dense OCCs.
- Efficient deduction in latent space : The predictive hidden world model “imagines” the future in a compact hidden space, avoiding the high computational cost of directly generating images, and achieving the unity of understanding the present and predicting the future.
- Real-time and accurate decision-making : The VLA-MoE architecture combines Action Expert, parallel decoding and discrete diffusion optimization to take into account trajectory generation accuracy and real-time requirements. .
- Efficient deployment on the client side : The law of software and hardware co-design shortens the architecture exploration cycle from months to days, and finds the optimal balance of accuracy and latency on automotive chips.
Comparison of similar competing products of MindVLA-o1
| Contrast Dimensions | MindVLA-o1 | Tesla FSD | Huawei ADS |
|---|---|---|---|
| Architectural route | Native multi-modal VLA unified architecture | End-to-end pure vision | End-to-end + multi-sensor fusion |
| perception scheme | Vision-based + LiDAR geometry prompts | pure visual | Multi-sensor fusion |
| reasoning ability | Hidden world model predicts the future | End-to-end implicit reasoning | Rules + AI hybrid |
| behavior generation | MoE+parallel decoding+discrete diffusion | End-to-end direct output | piecemeal decision making |
| Simulation training | Feed-forward reconstruction + reinforcement learning | Shadow mode + emulation | Data closed loop is the main focus |
| Deployment optimization | Software and hardware co-design law | Self-developed chip Dojo/HW4.0 | Ascend chip optimization |
| Application extension | Vehicle + Robot Universal VLA | Focus on autonomous driving | Focus on autonomous driving |
| technical stage | Physical AI/Embodied Intelligence | AI-based end-to-end | AI-based end-to-end |
Application scenarios of MindVLA-o1
- Autonomous driving : MindVLA-o1, as the next-generation basic model of autonomous driving, can handle all-scenario driving tasks such as urban roads, highways, and complex intersections, and realize full-link intelligence from perception and understanding to decision-making and planning.
- Intelligent cockpit interaction : Relying on the language understanding capability of the native multi-modal architecture, the system can understand passengers’ voice instructions and combine with visual perception to achieve natural human-machine interaction and proactive services.
- Robot control : The same set of VLA models can be extended to the robot platform to drive different forms of embodied intelligence such as robotic arms and wheeled robots to complete tasks in the physical world.
- Simulation test verification : Generate high-fidelity virtual scenes through the MindSim world model, supporting large-scale closed-loop testing and model iteration of long-tail scenarios such as extreme weather and rare accidents.
- Intelligent traffic management : Based on 3D space understanding and prediction capabilities, it can be expanded to apply to city-level smart transportation systems such as vehicle-road collaboration and traffic flow prediction. ©
You May Also Like

Yuanbao Pai - Tencent Yuanbao's AI-powered social feature
What is Yuanbao Pai? Yuanbao Pai is an AI social feature launched by Tencent's Yuanbao app, making the AI Yuanbao a formal member of group chats and building a "human-machine symbiotic" social space. Users can @Yuanbao to chat at any time. Yuanbao Pai has a fun personality, can engage in witty banter and meme battles, and also possesses a super memory, accurately recalling details of group chats. Yuanbao Pai's functions include information summarization, document interpretation, scheduled task reminders, and image creation, supporting scenarios such as remote teaching and online movie viewing. Currently in the internal testing phase, it is attracting users to experience this new AI social model through a "share 1 billion yuan in red envelopes" campaign. Yuanbao Pai's main functions...
Meoo - Alibaba's cloud-based AI development tool
Homepage • AI Tools • Meoo - Alibaba's Cloud-Based AI Development Tool What is Meoo? Meoo is Alibaba's cloud-based AI development tool, positioned as an "all-around AI partner that can program, design, and self-deploy." The tool aggregates mainstream large models such as Kimi K2.5, Qwen3-Coder, and GLM-5, and supports Fast, Agent, Swarms...
Sub2API - An open-source AI API gateway platform that supports multi-account management
Sub2API is an open-source AI API gateway platform that supports unified access and management of subscriptions to mainstream AI services such as Claude, OpenAI, Gemini, and Antigravity. The platform provides features such as multi-account management, API Key distribution, token-level accurate billing, intelligent scheduling, and concurrency control.

PrismAudio - A video-to-audio generation framework launched by Alibaba Tongyi
PrismAudio, developed by Alibaba's Tongyi Lab, is a video-to-audio framework that automatically adds ambient sound effects to silent videos. The model pioneers a "decompositional thinking chain" technique, allowing it to first consider sound content, timing, texture, and spatial location before generating audio. It incorporates four "teachers" (semantic, temporal, aesthetic, and spatial) for multi-dimensional scoring and optimization. With only 518 million parameters, the model generates 9 seconds of audio in just 0.63 seconds, significantly outperforming existing methods. It has been accepted by ICLR 2026. PrismAudio's main functions...